1. 报错:
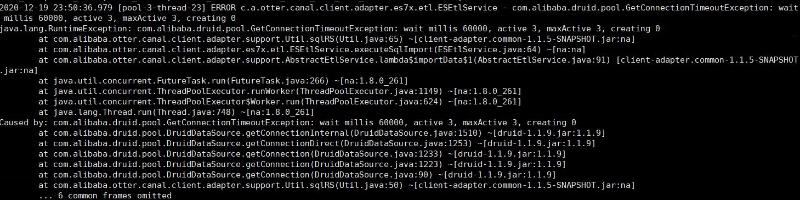
Caused by: com.alibaba.druid.pool.GetConnectionTimeoutException: wait millis 60000, active 3, maxActive 3, creating 0 at原因分析
查看 canal 源码得知当同步的数据量大于1w时,会分批进行同步,每批1w条记录,并使用多线程来并行执行任务,而 adapter 默认的连接池为3,当线程获取数据库连接等待超过1分钟就会抛出该异常。
线程数为当前服务器cpu的可用线程数
解决方式
修改 adapter 的 conf/application.yml 文件中的 srcDataSources 配置项,增加 maxActive 配置数据库的最大连接数为当前服务器cpu的可用线程数
cpu线程数可以下命令查看
grep 'processor' /proc/cpuinfo | sort -u | wc -lsrcDataSources:
defaultDS:
url: 这里填源数据库的jdbc连接信息,例:jdbc:mysql://127.0.0.1:3306/testdb
username: 数据库账号,例:root
password: 数据库密码,例:root
maxActive: 100 #额外增加这一行,默认的连接数只有3,会导致全量同步出现异常,导致全量同步数据缺失,最好改大一点
canalAdapters:2. canal adapter数据量大情况下出现死锁
failed! ==>Deadlock found when trying to get lock; try restarting解决方法:
mysql数据库隔离级别调整为RC。
set global TRANSACTION ISOLATION level read COMMITTED;
show global variables like 'transaction_isolation';
-- 恢复为RR
-- set global TRANSACTION ISOLATION level repeatable read;3.es连接超时
当同步的表字段比较多时,几率出现以下报错
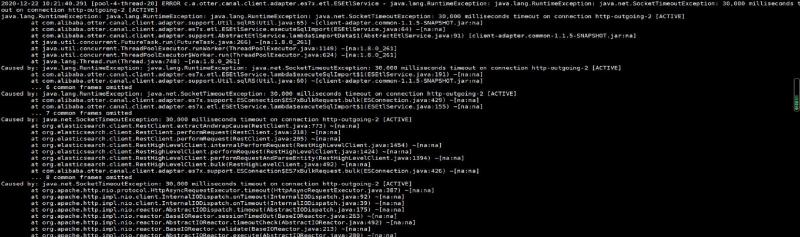
原因分析
由于 adapter 的表映射配置文件中的 commitBatch 提交批大小设置过大导致(6000)
解决方式
修改 adapter 的 conf/es7/xxx.yml 映射文件中的 commitBatch 配置项为3000
4. 同步慢
三千万的数据量用时3.5小时左右
原因分析
由于当数据量大于1w时 canal 会对数据进行分批同步,每批1w条通过分页查询实现;所以当数据量较大时会出现深分页的情况导致查询非常慢。
解决方式
预先使用ID、时间或者业务字段等进行数据分批后再进行同步,减少每次同步的数据量。
案例
使用ID进行数据分批,适合增长类型的ID,如自增ID、雪花ID等;
- 查出 最小ID、最大ID 与 总数据量
- 根据每批数据量大小计算每批的 ID区间
计算过程:
- 最小ID = 1333224842416979257
- 最大ID = 1341698897306914816
- 总数据量 = 3kw
- 每次同步量 = 300w
(1) 计算同步的次数
总数据量 / 每次同步量 = 10(2) 计算每批ID的增量值
(最大ID - 最小ID) / 次数 = 847405488993555.9(3) 计算每批ID的值
最小ID + 增量值 = ID2
ID2 + 增量值 = ID3
...
ID9 + 增量值 = 最大ID(4) 使用分批的ID值进行同步
修改sql映射配置,的 etlCondition 参数:
etlCondition: "where id >= {} and id < {}"调用etl接口,并增加 params 参数,多个参数之间使用 ; 分割
curl -X POST http://127.0.0.1:8081/etl/es7/sys_user.yml?params=最小ID;ID2
curl -X POST http://127.0.0.1:8081/etl/es7/sys_user.yml?params=ID2;ID3
curl http://127.0.0.1:8081/etl/hbase/mytest_person2.yml -X POST -d "params=2018-10-21 00:00:00"注意:本文归作者所有,未经作者允许,不得转载

