文末免费送电子书:七月在线干货组最新 升级的《名企 AI 面试 100 题》免费送!
本书涵盖计算机语 ⾔基础、算法和 ⼤数据、机器学习、深度学习、应 ⽤ ⽅向 (CV、NLP、推荐 、⾦融风控)等五 ⼤章节。
项目一:pytorchOCR — 基于 pytorch 的 ocr 算法库

已完成模型:
- DBnet
- PSEnet
- PANnet
- SASTnet
- CRNN
检测模型效果:训练只在 ICDAR2015 文本检测公开数据集上
模型压缩剪枝效果:
这里使用 mobilev3 作为 backbone,在 icdar2015 上测试结果,未压缩模型初始大小为 2.4M.
1 . 对 backbone 进行压缩
2 . 对整个模型进行压缩
模型蒸馏: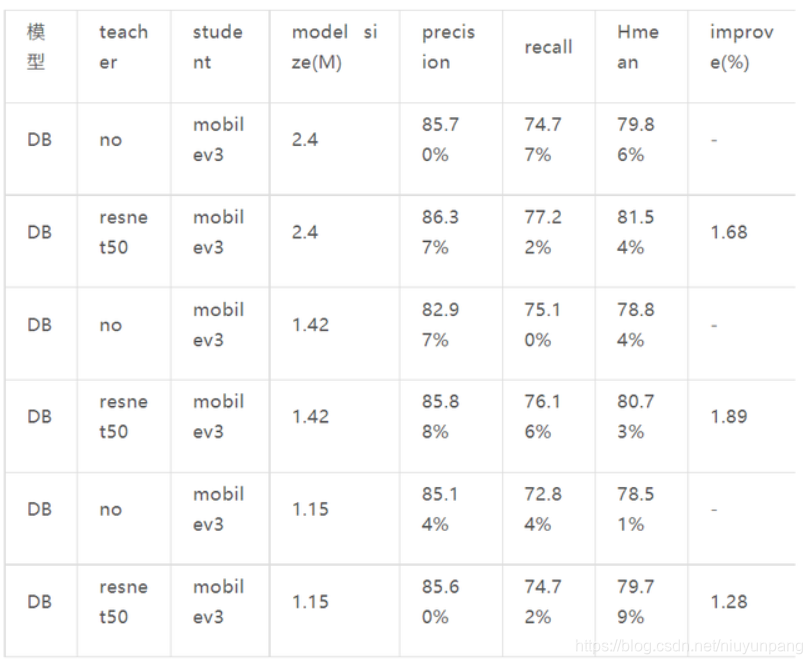
项目地址:
https://github.com/BADBADBADBOY/pytorchOCR
项目二:clothing-dataset — 服装数据集
超过 5000 张图片,20 个不同类别。
此数据集可自由用于任何目的,包括商业:例如:
- 创建教程或课程(免费或付费)
- 写一本书
- Kaggle 竞赛(作为外部数据集)
- 在任何公司培训内部模型
数据文件 images.csv 包括:
- image - 图像的 ID(使用它从 images/.jpg 加载图像)
- sender_id - 贡献图像的人的 ID
- label - 图像的类
- kids - 标记为“true”,说明它是孩子们的衣服
项目地址:
https://github.com/wbj0110/clothing-dataset
项目三:weibo-public-opinion-datasets — 持续维护的微博舆情数据集
新浪微博是中国最大的公共社交媒体平台。最新、最受欢迎的社交活动将尽快在微博上披露和讨论。因此,构建实时、全面的微博民意数据集具有十分重要的意义。
目前,在指定的关键字和指定期限内,构建微博推文数据集的方法有两种:
(1)应用微博给出的高级搜索 API:
(2) 浏览所有微博用户,在指定时间段内收集所有推文,然后使用指定的关键字过滤推文。
然而,对于第一种方法,由于微博搜索 API 的限制,一次性搜索的结果包含多达 1000 条推文,使得构建大规模数据集变得困难。至于第二种方法,虽然我们可以构建大型数据集,几乎没有遗漏,但穿越所有数十亿的微博用户需要很长的时间和大量的带宽资源。此外,大量微博用户处于非活动状态,浏览其主页是没有意义的,因为他们不得在指定时间段内发布任何推文。
为了缓解这些局限性,我们提出了一种构建微博微博数据集的新方法,可以构建具有高建设效率的大型数据集。具体来说,我们首先构建并动态维护一个高基质微博活动用户池(只是所有用户的一小部分),然后我们只浏览这些用户,并在指定期间使用指定的关键字收集他们所有的推文。
基于种子用户和通过社会关系的持续扩展,我们首先建立了一个包含超过 2.5 亿用户的微博用户库。活动微博用户池基于微博用户池构建,遵循 4 条规则: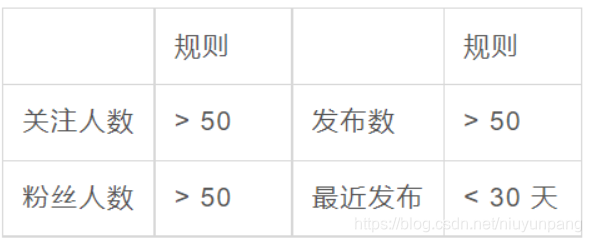
最后,我们构建了一个拥有 2000 万用户的微博活跃用户库,占微博用户总数的 8%。
项目地址:
https://github.com/nghuyong/weibo-public-opinion-datasets
项目四:scalene — Python 的高性能 CPU 内存分析器
Scalene 是一个 Python 的高性能 CPU 和 内存分析器,它可以做到很多其他 Python 分析器不能做到的事情。它在能提供更多详细信息的同时,比其他的分析器要快几个数量级。
- 本文地址:AI 开源项目精选 | 基于 pytroch 的 ORC 算法库及 python 高性能 CPU 分析等
- 本文版权归作者和AIQ共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出
Scalene 是 很快的。它使用采样的方式而不是直接测量或者依靠 Python 的追踪工具。它的开销一般不超过 10-20% (通常更少)。
Scalene 是 精确的。和大部分其他的 Python 分析器不同,Scalene 在 行级别 下执行 CPU 分析,在你的程序中指出对应代码行的执行时间。和大多数分析器所返回的功能级分析结果相比,这种程度的细节可能会更有用。
Scalane 可以区分在 Python 中运行的时间和在 native 代码(包括库)中花费的时间。大多数的 Python 程序员并不会去优化 native 代码(通常在 Python 实现中或者所依赖的外部库),所以区分这两种运行时间,有助于开发者能够将优化的工作专注于他们能够实际改善的代码上。
Scalene 可以 分析内存使用情况。除了追踪 CPU 使用情况,Scalene 还指出对应代码行的内存增长。这是通过指定内存分配器来实现的。
Scalene 会生成 每行 的内存分析,以此更容易的追踪内存泄露。
Scalene 会分析 内存拷贝量, 从而易于发现意外的内存拷贝。特别是因为跨越 Python 和底层库的边界导致的意外 (例如:意外的把 numpy 数组转化成了 Python 数组,反之亦然)。
功能比较分析:
项目地址:
https://github.com/plasma-umass/scalene
项目五:SDV — 用于表格、关系和时间系列数据的合成数据生成
Synthetic Data Vault (SDV) 是一个合成数据生成生态系统库,允许用户轻松学习单表、多表和时间系列数据集,以便日后生成与原始数据集具有相同格式和统计属性的新合成数据。
然后,合成数据可用于补充、增强,在某些情况下,在训练机器学习模型时替换真实数据。此外,它还允许对机器学习或其他数据依赖软件系统进行测试,而不会面临数据披露带来的暴露风险。
项目使用几个概率图形建模和基于深度学习的技术。为了实现各种数据存储结构,我们采用独特的分层生成建模和递归采样技术。
当前功能和特定:
具有以下功能的单台合成数据生成器:
- 使用基于科普拉斯和深度学习的模型。
- 以最少的用户输入处理多个数据类型和缺失数据。
- 支持预定义和自定义约束和数据验证。
- 合成数据生成器,用于复杂的多表、关系数据集,具有以下功能:
- 使用自定义和灵活的 JSON 模式定义整个多表数据集元数据集 。
- 使用科普拉斯和递归建模技术。
- 合成数据生成器,用于多类型、多变型时间系列,具有以下功能:
- 使用统计、自动回归和深度学习模型。
- 基于上下文属性的有条件采样。
项目地址:
https://github.com/sdv-dev/SDV
项目六:TensorflowASR — 集成 Tensorflow 2 版本的端到端语音识别模型
参照 librosa 库,用 TF2 实现了语音频谱特征提取的层,这样在跨平台部署时会更加容易。
快速使用:
- 下载预训练模型,修改 am_data.yml/lm_data.yml
里的目录参数(running_config 下的 outdir 参数),并在修改后的目录中添加 checkpoints 目录, - 将 model_xx.h5(xx 为数字)文件放入对应的 checkpoints 目录中,
- 修改 run-test.py 中的读取的 config 文件(am_data.yml,model.yml)路径,运行 run-test.py 即可。
C++ 的 demo 已经提供。测试于 TensorflowC 2.3.0 版本
项目地址:
https://github.com/Z-yq/TensorflowASR
**帮助数千人成功上岸的《名企AI面试100题》书,电子版,限时免费送,评论区回复“100题”领取!**
本书涵盖计算机语 ⾔基础、算法和 ⼤数据、机器学习、深度学习、应 ⽤ ⽅向 (CV、NLP、推荐 、⾦融风控)等五 ⼤章节,每 ⼀段代码、每 ⼀道题 ⽬的解析都经过了反复审查或 review,但不排除可能仍有部分题 ⽬存在问题,如您发现,敬请通过官 ⽹/APP 七月在线 - 国内领先的 AI 职业教育平台 (julyedu.com)对应的题 ⽬页 ⾯留 ⾔指出。
为了照顾 ⼤家去官 ⽹对应的题 ⽬页 ⾯参与讨论,故本 ⼿册各个章节的题 ⽬顺序和官 ⽹/APP 题库内的题 ⽬展 ⽰顺序 保持 ⼀致。 只有 100 题,但实际笔试 ⾯试不 ⼀定局限于本 100 题,故更多烦请 ⼤家移步七 ⽉在线官 ⽹或 七 ⽉在线 APP,上 ⾯还有近 4000 道名企 AI 笔试 ⾯试题等着 ⼤家,刷题愉快。
注意:本文归作者所有,未经作者允许,不得转载

