作者|Amol Mavuduru
编译|VK
来源|Towards Data Science
原文链接:https://towardsdatascience.com/how-you-can-build-simple-recommender-systems-with-surprise-b0d32a8e4802
如果你曾经参与过数据科学项目,对于某些任务,那么你可能会选一些常见的库。
例如大多数人可能会使用Pandas进行数据操作,使用Scikit learn进行通用机器学习,使用TensorFlow或PyTorch进行深度学习。但是你会用什么来建立一个推荐系统呢,Surprise可以帮助你。
Surprise是一个开源的Python库,它使开发人员可以轻松地用评分数据构建推荐系统。在本文中,我将向你展示如何使用Surprise来构建一个图书推荐系统,该系统使用Kaggle上的goodbooks-10k数据集,该数据集在CC BY-sa4.0许可下提供:https://www.kaggle.com/zygmunt/good。
安装
你可以使用以下命令使用pip安装Surprise。
pip install scikit-surprise
如果你希望使用Anaconda进行包管理,那么可以使用以下命令在Anaconda中安装Surprise。
conda install -c conda-forge scikit-surprise
如果你想直接从GitHub安装库的最新版本,应该使用以下命令(你将需要Numpy和Cython)。
pip install numpy cython
git clone https://github.com/NicolasHug/surprise.git
cd surprise
python setup.py install
建立图书推荐系统
你可以在GitHub上找到这个实际示例的完整代码:github.com/AmolMavuduru/SurprisePythonExamples
导入库
首先,我导入了一些用于数据操作和可视化的基本库。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
读取数据集
我使用了Kaggle上goodbooks-10k数据集中的两个CSV文件。第一个包含了10000本书的评分数据,这些图书被53000多个用户评过。第二个文件包含10000本书的元数据(标题、作者、ISBN等)。
ratings_data = pd.read_csv('./data/ratings.csv.zip')
books_metadata = pd.read_csv('./data/books.csv.zip')
ratings_data.head(10)
创建Surprise数据集
为了使用Surprise训练推荐系统,我们需要创建一个数据集对象。Surprise数据集对象是按以下顺序包含以下字段的数据集:
- 用户ID
- 项目ID(在本例中为每本书的ID)
- 相应的评分(通常是1-5分)
from surprise import Dataset
from surprise import Reader
reader = Reader(rating_scale=(1, 5))
data = Dataset.load_from_df(ratings_data[['user_id', 'book_id', 'rating']], reader)
简单SVD模型的训练与交叉验证
我们可以训练和交叉验证一个SVD(奇异值分解)模型,以便在几行代码中构建一个推荐系统。SVD是一种流行的矩阵分解算法,可用于推荐系统。
使用矩阵分解的推荐系统通常遵循这样一种模式:将评分矩阵分解为表示项目(在本例中为书籍)和用户的潜在因素的矩阵乘积。
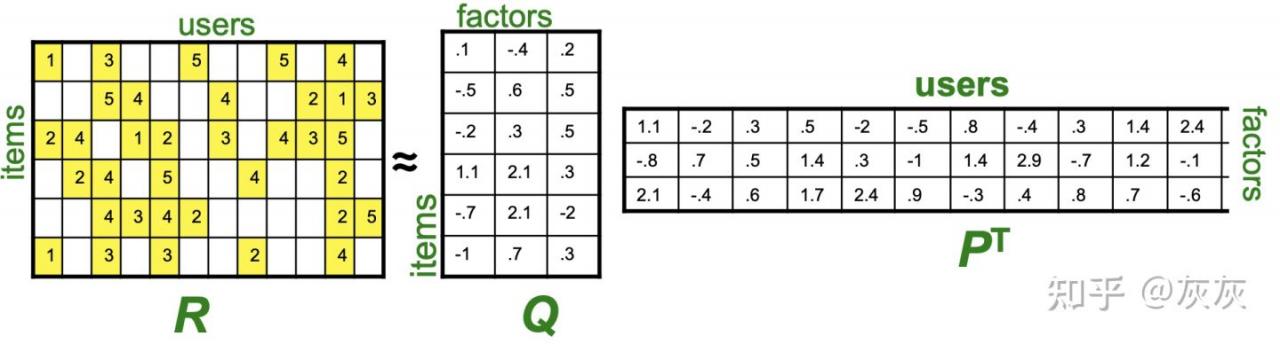

考虑上图,请注意评分矩阵R在某些地方的值是缺失的。在使用矩阵因子预测现有评分时,矩阵分解算法使用梯度下降等过程来最小化误差。因此,像SVD这样的算法通过允许我们“填补评分矩阵中的空白”来构建推荐系统,预测每个用户将给数据集中的每个商品分配的评分。
从输入矩阵A开始,SVD实际上将原始矩阵分解为三个矩阵,如下图所示。
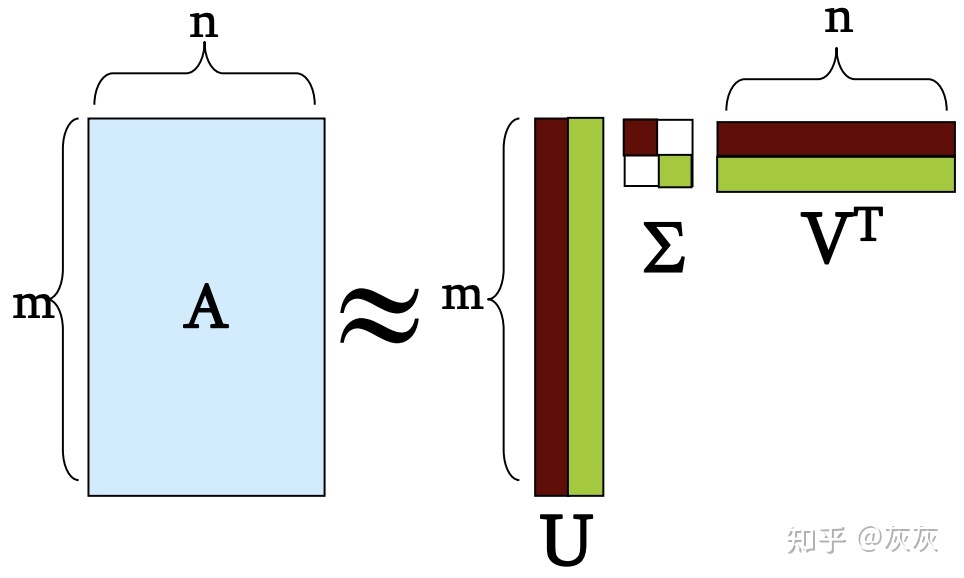

我们可以将这些新矩阵映射到评分矩阵R以及项目和用户因素Q和P,如下所示:
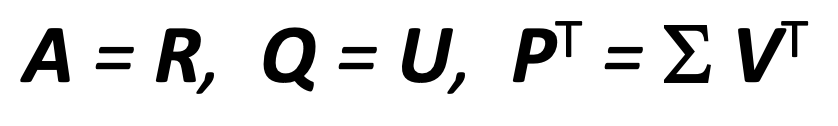

在图书推荐系统中,SVD算法将评分矩阵表示为分别表示图书因素和用户因素的矩阵的乘积。当然,这是一个非常简短的SVD算法的解释,没有所有的数学细节,如果你想更详细地解释这个算法,你应该看看斯坦福CS246课堂讲稿:http://snap.stanford.edu/class/cs246-2015/handouts.html?。
在下面的代码中,我使用三重交叉验证对SVD模型进行了交叉验证。
from surprise import SVD
from surprise.model_selection import cross_validate
svd = SVD(verbose=True, n_epochs=10)
cross_validate(svd, data, measures=['RMSE', 'MAE'], cv=3, verbose=True)
运行上面的代码生成以下输出。
Fold 1 Fold 2 Fold 3 Mean Std
RMSE (testset) 0.8561 0.8577 0.8551 0.8563 0.0011
MAE (testset) 0.6753 0.6764 0.6746 0.6754 0.0007
Fit time 20.21 22.62 23.25 22.03 1.31
Test time 3.18 4.68 4.79 4.22 0.74
在使用build_full_trainset方法将交叉验证的数据集转换为一个Surprise的Trainset对象之后,我们还可以使用fit方法在整个数据集上训练模型。
trainset = data.build_full_trainset()
svd.fit(trainset)
生成评分预测
现在我们已经有了一个经过训练的SVD模型,我们可以使用它来预测给定用户ID(UID)和项目/书籍ID(IID)的用户对图书的评分。下面的代码演示了如何使用predict方法实现这一点。
svd.predict(uid=10, iid=100)
predict方法返回如下所示的预测,其中包含一个名为est的字段,该字段指示此特定用户的估计图书评分。
Prediction(uid=10, iid=100, r_ui=None, est=4.051206489275292, details={'was_impossible': False})
根据上面的输出,我们可以看到这个模型预测这个特定的用户会给这本书一个四星的评分。这个模型不直接推荐书籍,但是我们可以使用这个评分预测工具来确定用户可能会喜欢什么书,这样就可以向用户推荐它们。
生成图书推荐
使用这个评分预测实用程序,我定义了以下实用程序函数来生成图书推荐。
import difflib
import random
def get_book_id(book_title, metadata):
"""
根据元数据数据帧中最接近的匹配获取书名的图书ID。
"""
existing_titles = list(metadata['title'].values)
closest_titles = difflib.get_close_matches(book_title, existing_titles)
book_id = metadata[metadata['title'] == closest_titles[0]]['id'].values[0]
return book_id
def get_book_info(book_id, metadata):
"""
给定图书id和元数据数据框架,返回有关图书的一些基本信息。
"""
book_info = metadata[metadata['id'] == book_id][['id', 'isbn',
'authors', 'title', 'original_title']]
return book_info.to_dict(orient='records')
def predict_review(user_id, book_title, model, metadata):
"""
预测用户对某本书的评论(1-5分)。
"""
book_id = get_book_id(book_title, metadata)
review_prediction = model.predict(uid=user_id, iid=book_id)
return review_prediction.est
def generate_recommendation(user_id, model, metadata, thresh=4):
"""
根据评分阈值为用户生成图书推荐。只有预测评分达到或高于阈值的书籍才会被推荐
"""
book_titles = list(metadata['title'].values)
random.shuffle(book_titles)
for book_title in book_titles:
rating = predict_review(user_id, book_title, model, metadata)
if rating >= thresh:
book_id = get_book_id(book_title, metadata)
return get_book_info(book_id, metadata)
generate_recommendation函数通过迭代无序排列的图书标题列表并预测每个标题的用户评分,为用户生成一个图书推荐,直到找到一本评分达到或高于指定阈值的图书,从而使其有资格推荐给用户。在开始的时候重新排列书名会给推荐书增加一些随机性。
generate_recommendation(1000, svd, books_metadata)
运行上面演示的函数会产生下面的输出(注意,由于函数的随机性,你可能会得到不同的建议)。
[{'id': 7034,
'isbn': '1402792808',
'authors': 'Corban Addison',
'title': 'A Walk Across the Sun',
'original_title': 'A Walk Across the Sun'}]
根据上面的输出,我们可以看到函数返回一个字典,其中包含关于推荐书籍的元数据。多次运行此函数将生成多个图书推荐。在用户阅读了一本书之后,我们可以将这些数据添加到评分数据中,并重新训练模型以生成更好的推荐系统。
用t-SNE可视化图书因素
我们可以让这个项目更进一步,根据图书因素矩阵,在前面用来解释矩阵因子分解模型的图中称为Q,来可视化书籍之间的相似性。
这个10000×100矩阵对每本书都有一个100维的向量,向量太多了,我们无法直观地可视化,但是我们可以使用降维技术将每本书表示为空间中的一个二维点。在下面的代码中,我使用了一种称为t-SNE(t-分布随机邻居嵌入)的技术,将每本书表示为一个二维点,并将结果存储在一个数据帧中。
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2, n_iter=500, verbose=3, random_state=1)
books_embedding = tsne.fit_transform(svd.qi)
projection = pd.DataFrame(columns=['x', 'y'], data=books_embedding)
projection['title'] = books_metadata['original_title']
在为每本书创建了带有二维点的数据框之后,我使用Plotly创建了一个可视化,其中每个点对应于原始数据集中的一本书。
import plotly.express as px
fig = px.scatter(
projection, x='x', y='y'
)
fig.show()
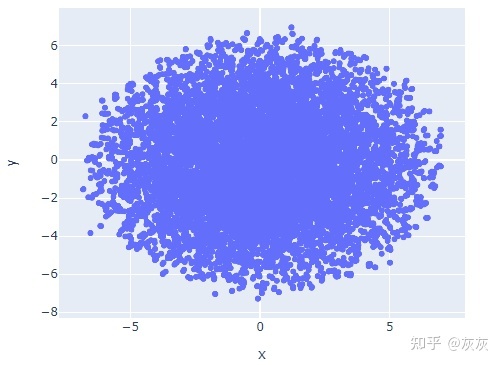

基于上面plot代码生成的图,我们可以看到代表10000本书的点似乎遵循二维正态分布。我们可以用以下关于书籍的理论来解释这种分布:
- 有些书可能在广泛的读者中普遍流行,因此对应于这个散点图的中心点。
- 其他的书可能会分为非常特定的类型,比如吸血鬼小说、神秘小说和爱情小说,它们在特定的读者中很受欢迎。这些书可能对应着远离散点图中心的点。
为了实际查看与每个点相关的书名,我定义了一个特定的函数来绘制给定书名的图书列表。注意,我使用了Datapane来显示嵌入在本文中的可视化效果。在下面的代码中,我添加了一个函数参数,用于将结果图发布为Datapane的报告。
import datapane as dp
def plot_books(titles, plot_name):
book_indices = []
for book in titles:
book_indices.append(get_book_id(book, books_metadata)-1)
book_vector_df = projection.iloc[book_indices]
fig = px.scatter(
book_vector_df, x='x', y='y', text='title',
)
fig.show()
report = dp.Report(dp.Plot(fig) ) #Create a report
report.publish(name=plot_name, open=True, visibility='PUBLIC')
使用下面的代码,我绘制了与数据集中前30本书相关的点。
books = list(books_metadata['title'][:30])
plot_books(books, plot_name='books_embedding')

这种可视化使我们能够看到不同书籍之间的相似之处。当涉及到相似用户提供的评分时,彼此距离较近的书籍往往表现相似。例如,我们可以看到,分别来自饥饿游戏和发散系列的两部小说《着火》和《发散》,在相似的用户中很受欢迎。
总结
- Surprise是一个易于使用的Python库,它允许我们快速构建基于评分的推荐系统,而无需重新设计轮子。
- 在使用SVD等模型时,Surprise还使我们能够访问矩阵因子,这使我们能够可视化数据集中项目之间的相似性。
如前所述,本文中关于GitHub的所有示例都包含了代码:https://github.com/AmolMavuduru/SurprisePythonExamples
参考引用
- N. Hug, Surprise: A Python library for recommender systems, (2020), Journal of Open Source Software.
- Z. Zajac, Goodbooks-10k dataset, (2017), Kaggle.
- J. Leskovec, Stanford CS 246 Mining Massive Datasets Lecture Notes, (2015), Stanford Network Analysis Project.
本文来自zhihu,观点不代表一起大数据-技术文章心得立场,如若转载,请注明出处:https://zhuanlan.zhihu.com/p/352181306
注意:本文归作者所有,未经作者允许,不得转载

