机器学习建模工具 PYCARET
- 1 PyCaret 1.0.0简介
- 2 PyCaret入门
- 3 获取数据
- 4 搭建环境
- 4.1 预处理介绍
- 4.2 采样与拆分
- 4.2.1 训练/测试数据拆分
- 4.2.2 采样(Sampling)
- 4.3 数据准备
- 4.3.1 缺失值处理
- 4.3.2 更改数据类型
- 4.3.3 独热编码(One Hot)
- 4.3.4 序数编码
- 4.3.5 基数编码
- 4.3.6 处理未知级别
- 4.4 数据规范化与转换
- 4.4.1 数据规范化 (Normalization)
- 4.4.2 数据转换
- 4.4.3 目标转换
- 4.5 特征工程
- 4.5.1 特征交互
- 4.5.2 多项式特征
- 4.5.3 三角特征
- 4.5.4 分组特征
- 4.5.5 分箱数字特征
- 4.5.6 合并稀有级别
- 4.6 特征选择
- 4.6.1 特征重要性
- 4.6.2 消除多重共线性
- 4.6.3 主成分分析
- 4.6.4 忽略低方差
- 4.7 无监督
- 4.7.1 创建聚类
- 4.7.2 删除异常值
- 5 模型训练
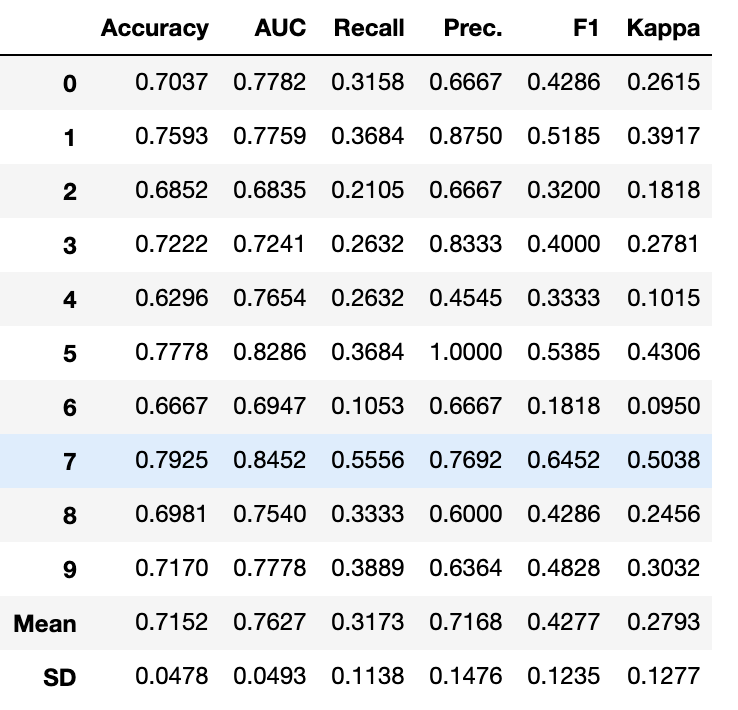
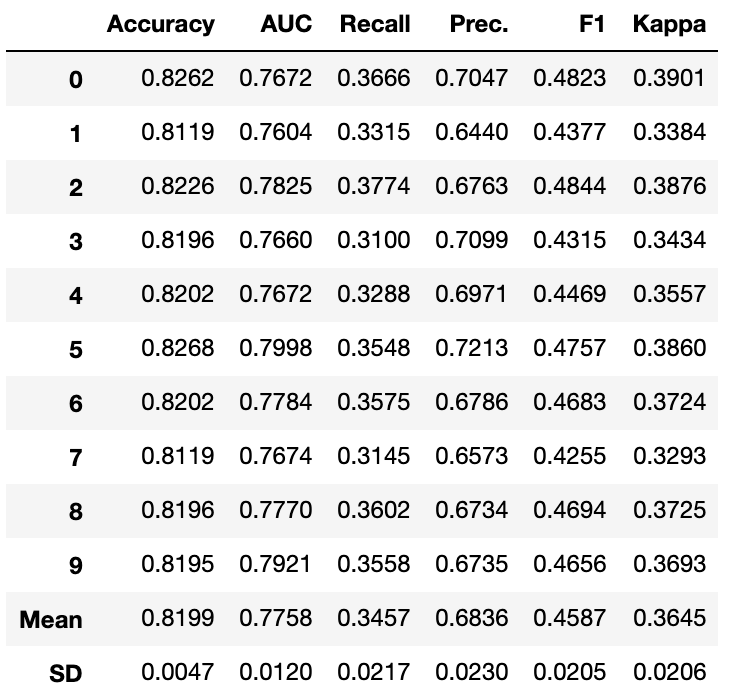
- 5.1 比较模型
- 5.1.1 分类示例
- 5.1.2 回归示例
- 5.2 创建模型
- 5.2.1 分类
- 5.2.2 回归
- 5.2.3 聚类
- 5.2.4 异常检测
- 5.2.5 关联规则挖掘
- 5.3 调优模型
- 5.3.1 分类示例
- 5.3.2 回归示例
- 5.3.3 聚类示例
- 5.3.4 异常检测实例
- 5.1 比较模型
- 6 集成模型
- 6.1 Bagging
- 6.2 Boosting
- 6.3 Stack
- 6.4 Blend
- 6.4.1 分类示例
- 6.4.2 回归示例
- 7 解释模型
- 7.1 显示模型
- 7.1.1 分类
- 7.1.2 回归
- 7.1.3 聚类
- 7.1.4 异常检测
- 7.1.5 关联规则挖掘
- 7.2 解释模型
- 7.2.1 汇总图
- 7.2.2 相关图
- 7.2.3 观察层面的因果图
- 7.2.4 分配模型
- 7.2.5 校准模型
- 7.2.6 优化阈值
- 7.1 显示模型
- 8 预测模型
- 9 部署模型
- 9.1 定型模型
- 9.2 部署模型
- 9.3 使用部署模型的预测
- 9.4 保存模型
PYCARET 1.0.0简介
PyCaret是一个使用Python的开源机器学习库,用于在Windows上训练和部署有监督和无监督的机器学习模型低码环境。通过PyCaret,您可以在选择笔记本电脑环境后的几秒钟内,从准备数据到部署模型。
与其他开源机器学习库相比,PyCaret是一个备用的低代码库,可用于仅用很少的单词替换数百行代码。这使得实验快速而有效地成指数增长。PyCaret本质上是Python的包装器,它围绕着多个机器学习库和框架,例如scikit-learn,XGBoost,Microsoft LightGBM,spaCy等。
PYCARET入门
可以安装PyCaret的第一个稳定版本(PyCaret1.0.0)。使用命令行(command line)界面或笔记本(notebook)环境,运行下面的代码单元以安装PyCaret。
pip install pycaret
如果您使用的是 Jupyter Notebook,请运行以下代码单元以安装PyCaret
!pip install pycaret
当您安装PyCaret时,将自动安装所有依赖项。完整依赖项列表参照下方链接:https://github.com/pycaret/pycaret/blob/master/requirements.txt
没有比这更容易 ,现在来直观感受下PyCaret的强大。
获取数据
在本次循序渐进的教程中,我们将使用“糖尿病”数据集,目标是根据血压,胰岛素水平,年龄等多种因素来预测患者结果。直接使用 PyCaret 的get_data()函数加载数据(这需要internet连接),也可以通过使用Pandas从本地离线数据集中加载。
PyCaret的github仓库:https://github.com/pycaret/pycaret
# from pycaret.datasets import get_data
# diabetes = get_data('diabetes')
# 使用Pandas加载CSV
from pandas import read_csv
diabetes = read_csv('diabetes.csv')
diabetes.head()


特别提醒: PyCaret可以直接与pandas数据框(dataframe)一起使用。
本案例涉及到的数据集列表如下:
来自UCI机器学习数据资源库:http://archive.ics.uci.edu/ml/index.php
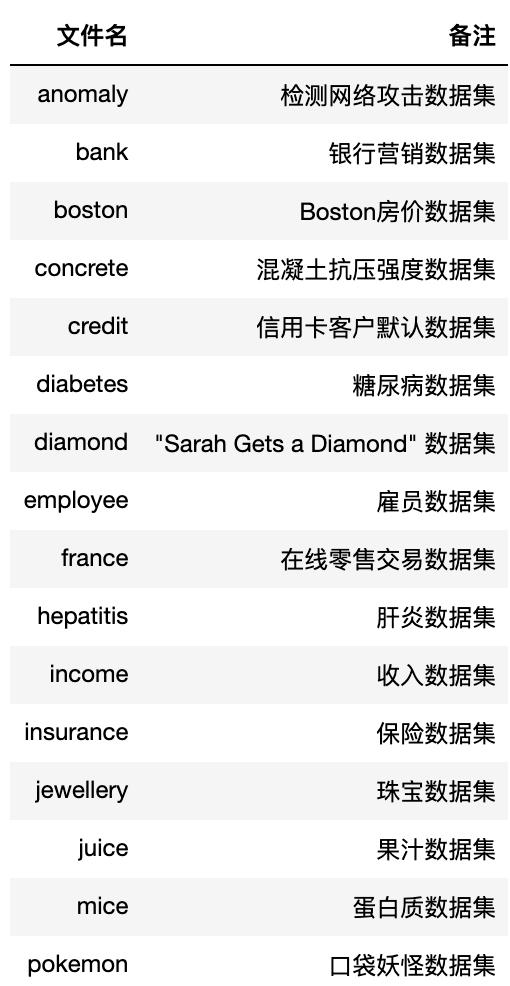

国内数据集:
阿里云天池实验室:https://tianchi.aliyun.com/dataset/?spm=5176.14154004.J_4373131660.12.31fe5699PmM1g2
Kesci 和鲸社区 :?https://www.kesci.com/home/dataset
搭建环境
PyCaret中任何机器学习实验的第一步都是通过导入所需的模块并初始化setup()来设置环境的。
函数?setup()?初始化pycaret中的环境,并创建转换管道以准备建模和部署数据。在pycaret中执行任何其他函数之前必须调用?setup()。它接受两个必需参数:pandas数据帧和目标列的名称。所有其他参数都是可选的,用于自定义预处理管道。
当执行?setup()?时,PyCaret的推理算法将根据某些特征自动推断所有特征的数据类型。应该正确推断数据类型,但情况并非总是如此。为此,PyCaret显示一个表,其中包含执行?setup()?后的特征及其推断的数据类型。如果所有数据类型都正确标识,则可以按?enter?继续,或键入?quit?结束实验。在PyCaret中,确保数据类型是正确的是非常重要的,因为PyCaret会自动执行一些预处理任务,这对于任何机器学习实验都是必不可少的。对于每种数据类型,这些任务的执行方式不同,这意味着正确配置它们非常重要。
本示例中使用的模块是pycaret.classification。导入模块后,将通过定义数据框(‘diabetes’)和目标变量(‘Class variable’)来初始化setup()。
from pycaret.classification import *
exp1 = setup(diabetes, target = 'Class variable')
PyCaret是一个部署就绪的Python库,这意味着当您执行一个实验时,所有步骤都会自动保存在一个管道中,可以轻松地部署到生产环境中。PyCaret自动编排管道中的所有依赖项。一旦开发了一个管道,它就可以被转移到另一个环境中进行大规模运行。所有的预处理和数据准备任务都是PyCaret中的管道的一部分,在使用setup初始化实验时开发该管道。
预处理介绍
所有预处理步骤都在setup()中应用。PyCaret拥有20多种功能,可为机器学习准备数据,它会根据setup函数中定义的参数创建转换管道(transformation pipeline)。
它会自动编排管道(pipeline)中的所有依赖项,因此您不必手动管理对测试数据集或未知的数据集进行转换的顺序执行。PyCaret的管道可以轻松地在各种环境之间转移,以实现大规模运行或轻松部署到生产环境中。以下是PyCaret首次发布时可用的预处理功能。PyCaret的预处理能力如下图:
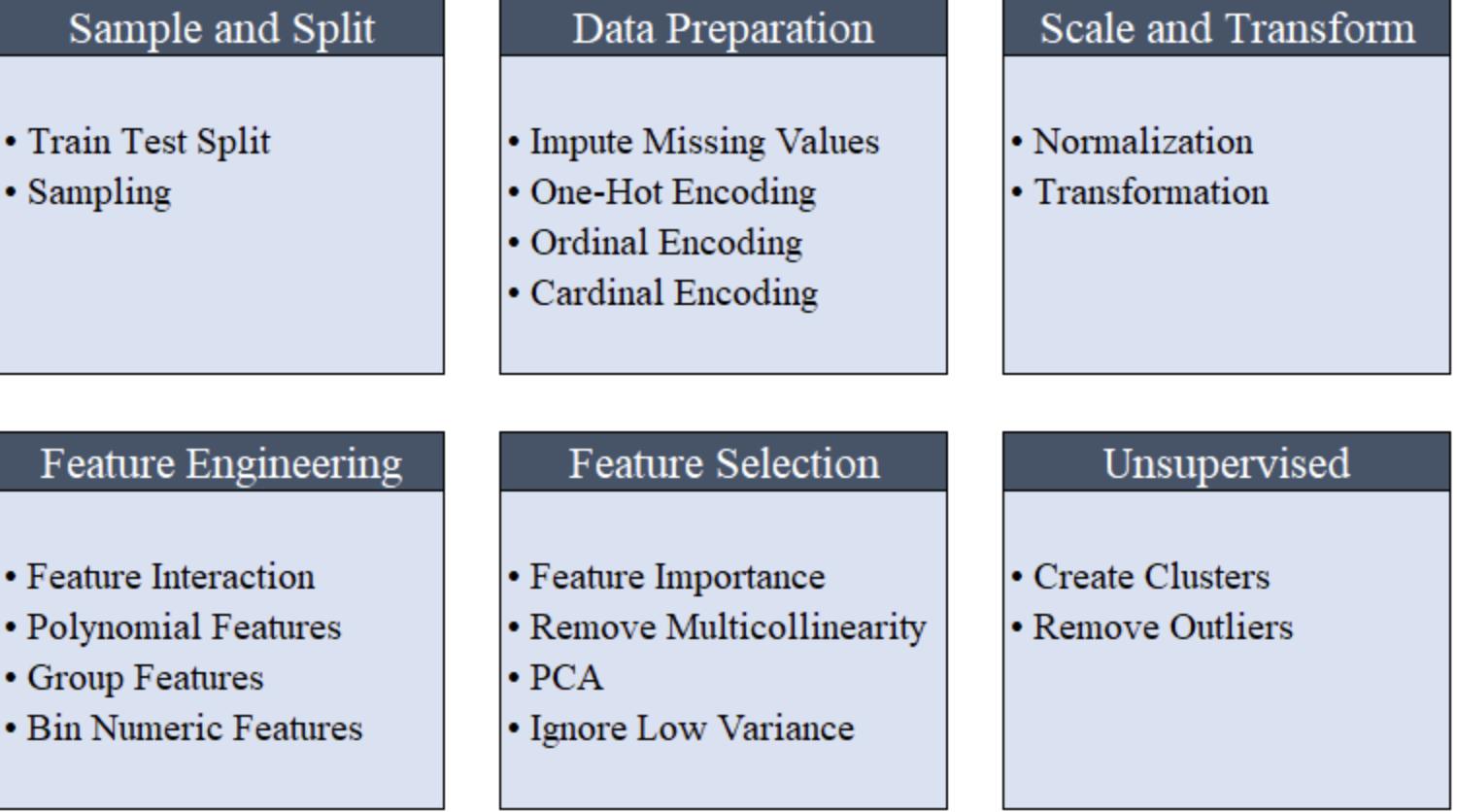

特别提醒:当setup()初始化时,将自动执行机器学习必需的数据预处理步骤,例如缺失值插补,分类变量编码,标签编码(将yes或no转换为1或0)和训练、测试集拆分(train-test-split)。
采样与拆分
训练/测试数据拆分
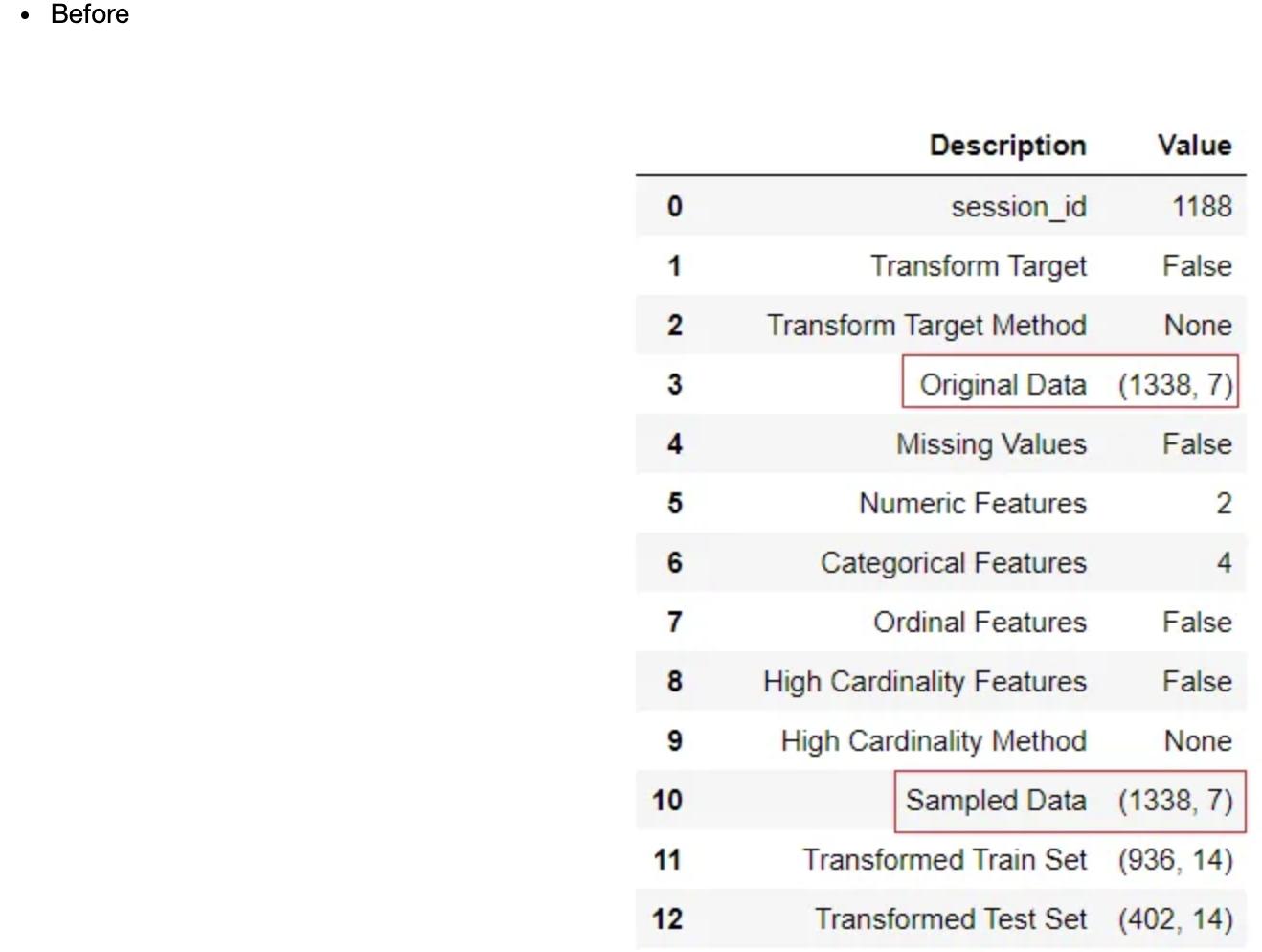
机器学习的目标是建立一个能很好地推广到新数据的模型。因此,在有监督的机器学习实验中,数据集被分为训练数据集和测试数据集。测试数据集充当新数据的代理。训练后的机器学习模型的评估和PyCaret中超参数的优化仅在训练数据集上使用k-fold交叉验证。测试数据集(也称为保持集)不用于模型的训练,因此可以在?predict_model?函数下用于评估度量和确定模型是否过度拟合数据。默认情况下,PyCaret使用70%的数据集进行训练,可以在设置中使用?train_size?参数更改。
此功能仅在pycaret.classification和pycaret.regression模块中可用。
# Importing dataset
insurance = read_csv('insurance.csv')
# Importing module and initializing setup
from pycaret.regression import *
'''
train_size: float, default = 0.7 训练集的大小。
默认情况下,70%的数据将用于训练和验证。
剩余数据将用于测试/保持集。
'''
reg1 = setup(data = insurance, target = 'charges', train_size = 0.7)


采样(SAMPLING)
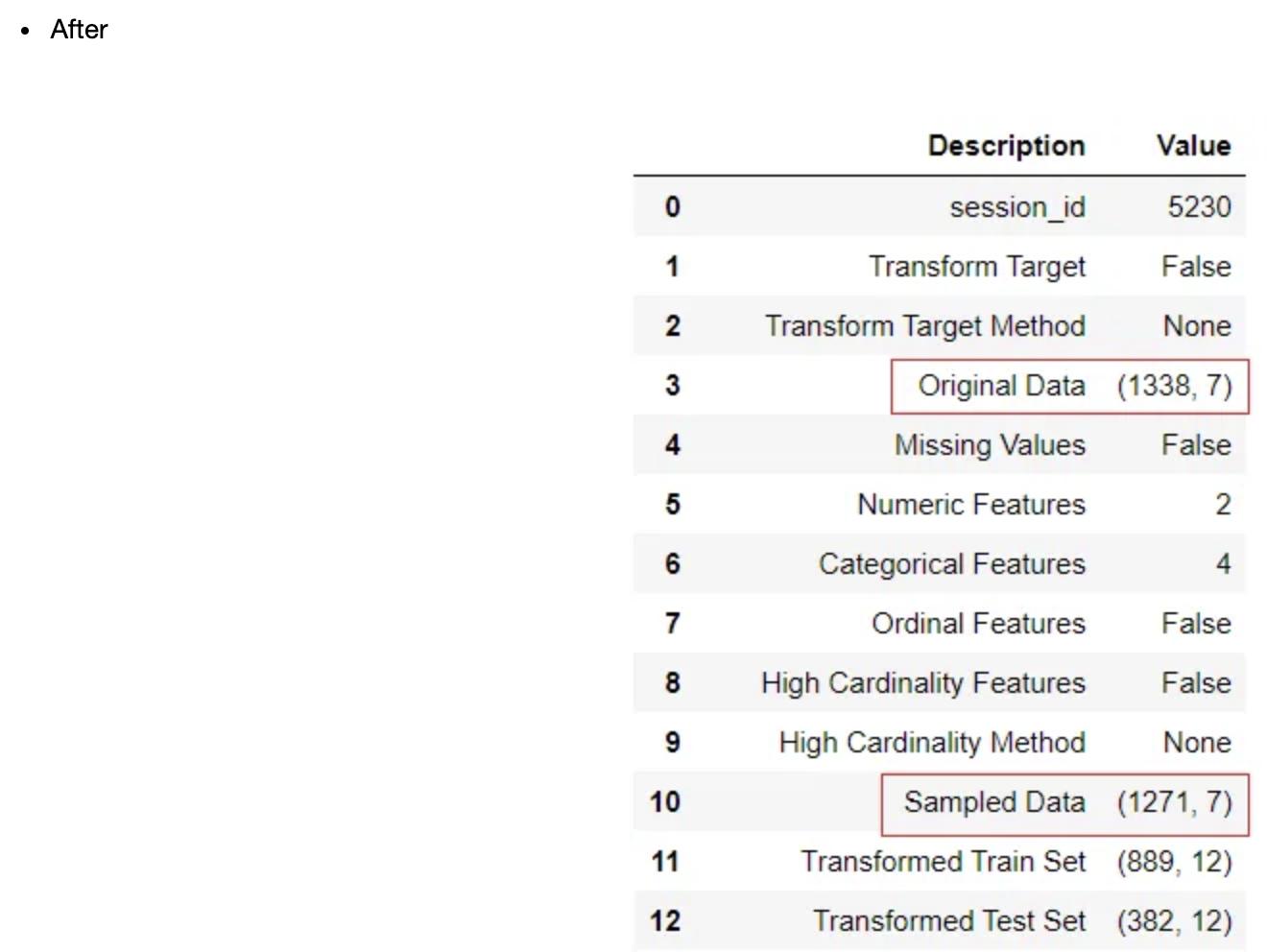
当数据集包含超过25000个样本时,PyCaret默认启用数据集的采样。它通过在不同的样本水平上训练一个初步的线性模型来实现这一目的,并打印出一个视觉效果图,显示了训练模型作为样本水平函数的性能,如x轴所示。然后,此图可用于评估用于训练模型的样本大小。有时,您可能希望选择较小的样本大小,以便更快地训练模型。为了改变线性模型的估计量,可以在setup中使用?sample_estimator?参数。要关闭采样,可以将采样参数设置为False。
此功能仅在pycaret.classification和pycaret.regression模块中可用。
# Importing dataset
bank = read_csv('bank.csv')
# Importing module and initializing setup
from pycaret.regression import *
'''
sampling: bool, default = True
sample_estimator: object, default = None ,如果 None, 则默认使用线性模型.
'''
reg1 = setup(data = bank, target = 'deposit')


当样本量超过25000个样本时,pycaret将根据原始数据集的不同样本量构建一个基本估计量。这将返回不同样本级别的通用评估度量的性能图,这将有助于确定建模的首选样本大小。然后必须输入所需的样本大小,以便在pycaret环境中进行训练和验证。当输入的?sample_size?小于1时,只有在调用?finalize_model()?时,才会使用剩余的数据集(1–sample)拟合模型。
数据准备
缺失值处理
由于各种原因,数据集可能有丢失的值或空记录,通常编码为空或NaN。大多数机器学习算法不能处理缺失或空白值。删除缺少值的样本是一种基本策略,有时会用到,但它会带来丢失可能有价值的数据和相关信息或模式的代价。一个更好的策略是估算缺失的值。默认情况下,PyCaret按数字特征的“平均值”和分类特征的“常量”输入数据集中缺少的值。要更改插补方法,可以在设置中使用?numeric_imputation?和?categorical_imputation?参数。
# Importing dataset
hepatitis = read_csv('hepatitis.csv')
# Importing module and initializing setup
from pycaret.classification import *
'''
numeric_imputation: string, default = ‘mean’
如果在数字特征中发现缺失值,则将用特征的平均值进行估算。
另一个可用的选项是“median”,它使用训练数据集中的中值来估算值。
categorical_imputation: string, default = ‘constant’
如果在分类特征中发现缺失的值,则将使用常量“not_available”值进行估算。
另一个可用的选项是“mode”,
它使用训练数据集中最频繁的值来估算缺失的值。
'''
clf1 = setup(data = hepatitis, target = 'Class')
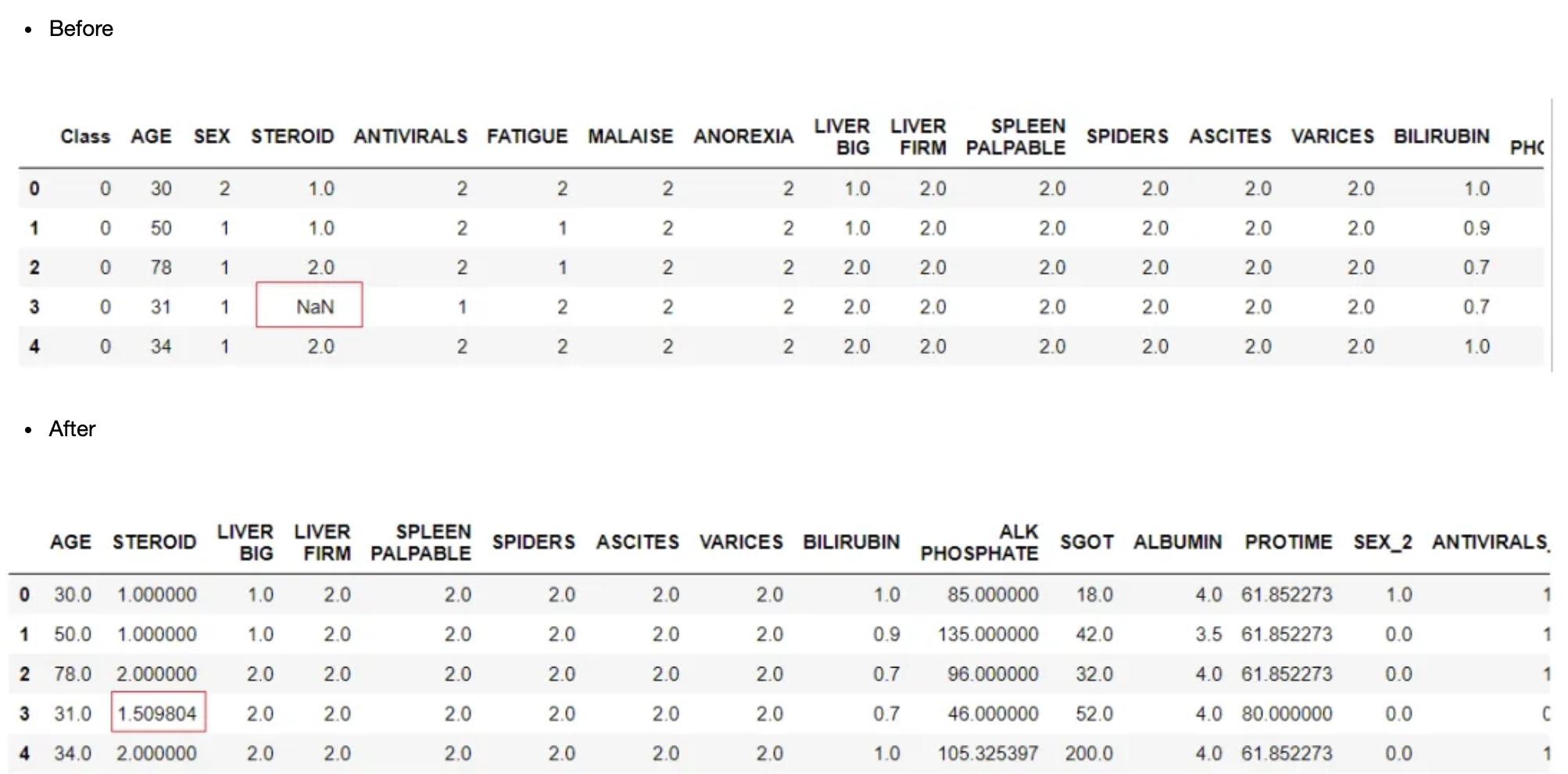

更改数据类型
数据集中的每个要素都有一个关联的数据类型,如数字要素、分类要素或日期时间要素。PyCaret的推理算法自动检测每个特征的数据类型。但是,有时PyCaret推断的数据类型是不正确的。确保数据类型正确非常重要,因为几个下游过程取决于特征的数据类型,例如:数字特征和分类特征的缺失值插补应分别执行。要覆盖推断的数据类型,可以在安装程序中传递数值特征、分类特征和日期特征参数。
# Importing dataset
hepatitis = read_csv('hepatitis.csv')
# Importing module and initializing setup
from pycaret.classification import *
'''
numeric_features: string, default = None
如果推断的数据类型不正确,则可以使用数值特征覆盖推断的类型。
如果在运行安装程序时,“column1”的类型被推断为类别而不是数字,
则可以使用此参数通过传递 numeric_features=['column1'] 来覆盖。
categorical_features: string, default = None
如果推断的数据类型不正确,则可以使用分类特征覆盖推断的类型。
如果在运行安装程序时“column1”的类型被推断为数值而不是类别,
则可以使用此参数通过传递 categorical_features=['column1'] 覆盖该类型。
date_features: string, default = None
如果数据有一个在运行安装程序时未自动检测到的DateTime列,
则可以通过传递 date_features='date_column_name' 来使用此参数。
它可以处理多个日期列。建模中不使用日期列。
相反,将执行特征提取,并从数据集中删除日期列。
如果日期列包含时间戳,则还将提取与时间相关的特征。
ignore_features: string, default = None
如果建模时应忽略任何特征,则可以将其传递给参数 ignore_features。
当推断出ID和DateTime列时,将自动设置为忽略以进行建模。
'''
clf1 = setup(data = hepatitis, target = 'Class', categorical_features = ['AGE'])
独热编码(ONE HOT)
机器学习算法不能直接处理分类数据,必须在训练模型之前将其转换为数值。最常见的分类编码类型是独热编码(也称为伪编码),其中每个分类级别成为包含二进制值(1或0)的数据集中的单独特征。由于这是执行ML实验的必要步骤,PyCaret将使用独热编码转换数据集中的所有分类特征。这对于具有名义分类数据(即数据无法排序)的特征非常理想。在其他不同的情况下,必须使用其他编码方法。例如,当数据是序数,即数据具有内在级别时,必须使用序数编码。独热编码可用于所有特征,这些特征要么被推断为分类特征,要么被强制使用设置中的?categorical_features?参数作为分类特征。
# Importing dataset
pokemon = read_csv('pokemon.csv')
# Importing module and initializing setup
from pycaret.classification import *
clf1 = setup(data = pokemon, target = 'Legendary')
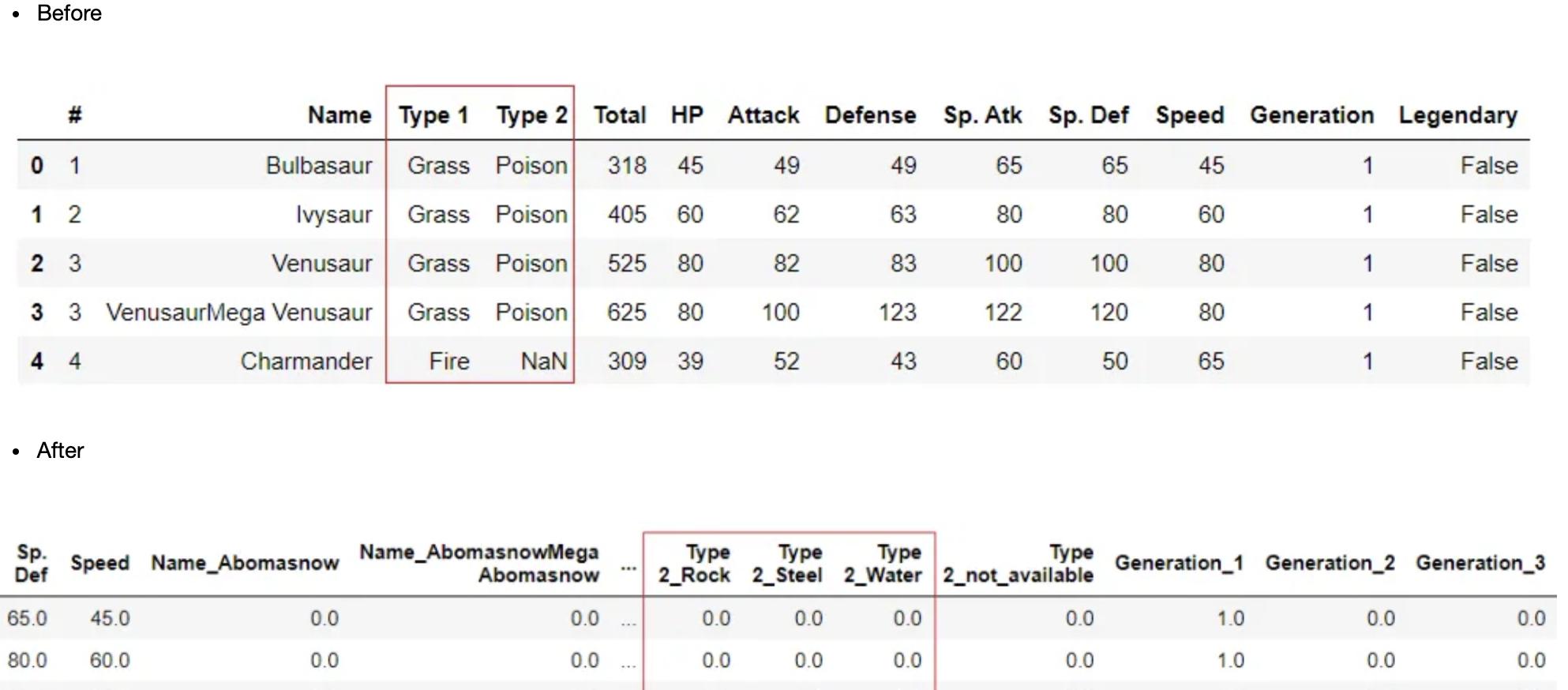

序数编码
当数据集中的分类特征包含具有内在自然顺序的变量(如低、中、高)时,这些变量的编码必须不同于名义变量(如男性或女性没有内在顺序)。这可以在PyCaret中使用setup中的?ordinal_features?参数来实现,该参数接受一个字典,其特征名称和级别按从低到高的顺序递增。
# Importing dataset
employee = read_csv('employee.csv')
# Importing module and initializing setup
from pycaret.classification import *
'''
ordinal_features: dictionary, default = None
当数据包含序数特征时,必须使用序数特征参数对它们进行不同的编码。
如果数据具有值为“low”、“medium”、“high”的分类变量,
并且已知low<medium<high,则可以将其作为 ordinal_features = { ‘column_name’ : [‘low’, ‘medium’, ‘high’] } 传递。
列表序列必须按从低到高的顺序递增。
'''
clf1 = setup(data = employee, target = 'left', ordinal_features = {'salary' : ['low', 'medium', 'high']})
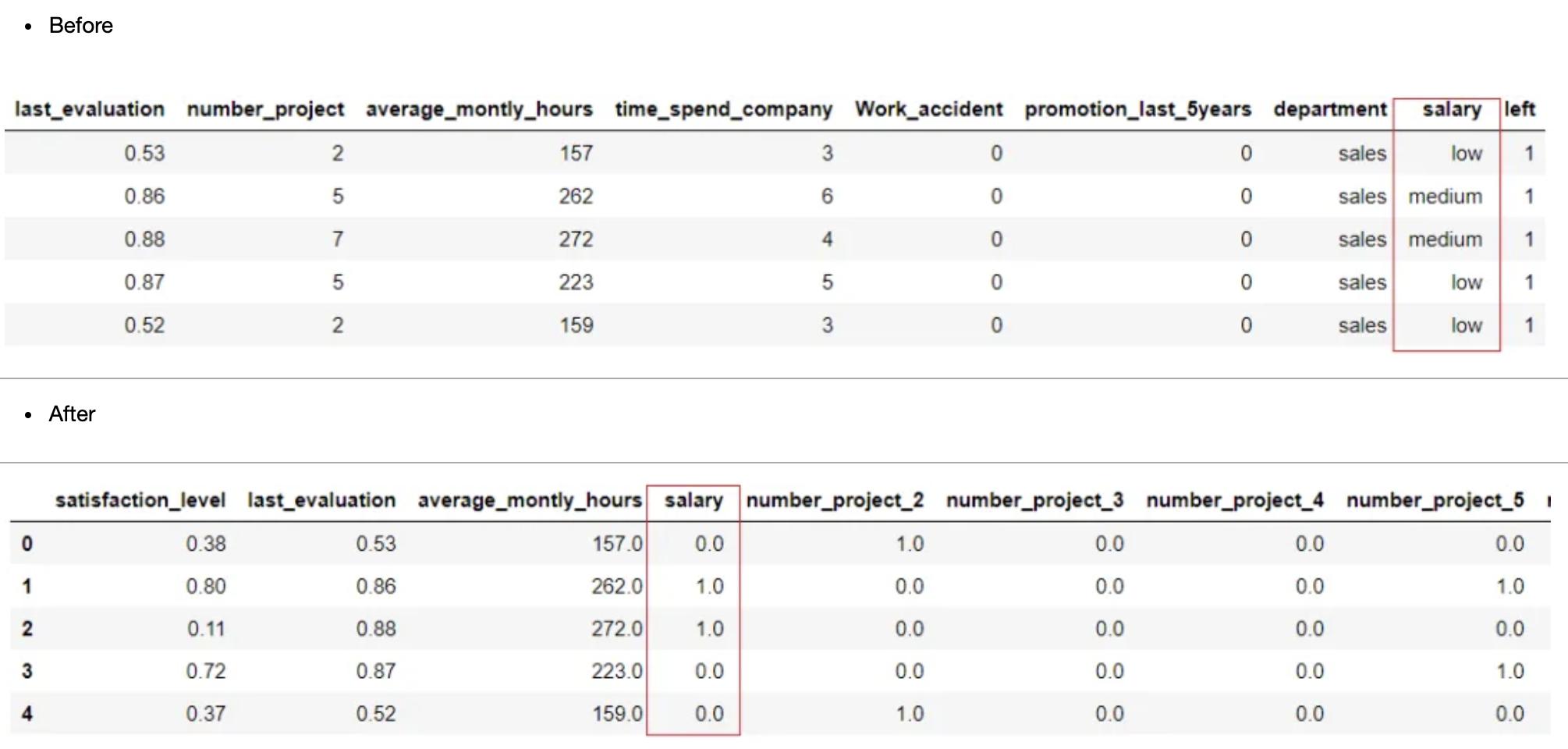

基数编码
当数据集中的分类特征包含多个级别的变量(也称为高基数特征)时,典型的独热编码会导致创建大量新特征,从而使实验变慢,并为某些机器学习算法引入可能的噪声。在PyCaret中,可以使用设置中的?high-cardinality-Features?参数处理具有高基数的特性。它支持两种基数编码方法,即基于频率/计数的方法和聚类方法。这些方法可以在setup中的?high_cardinality_method?参数中定义。
# Importing dataset
income = read_csv('income.csv')
# Importing module and initializing setup
from pycaret.classification import *
'''
high_cardinality_features: string, default = None
当数据包含具有高基数的特性时,可以通过将其作为具有高基数的列名列表传递来将其压缩为较少的级别。
使用 high_cardinality_method param 中定义的方法压缩特征。
high_cardinality_method: string, default = ‘frequency’
当方法设置为“frequency”时,它将用频率分布替换特征的原始值,并将特征转换为数值。
另一种可行的方法是“clustering”,它对数据的统计属性进行聚类,并用聚类标签代替特征的原始值。
使用Calinski-Harabasz和 Silhouette 准则的组合来确定簇的数量。
'''
clf1 = setup(data = income, target = 'income >50K', high_cardinality_features = ['native-country'])
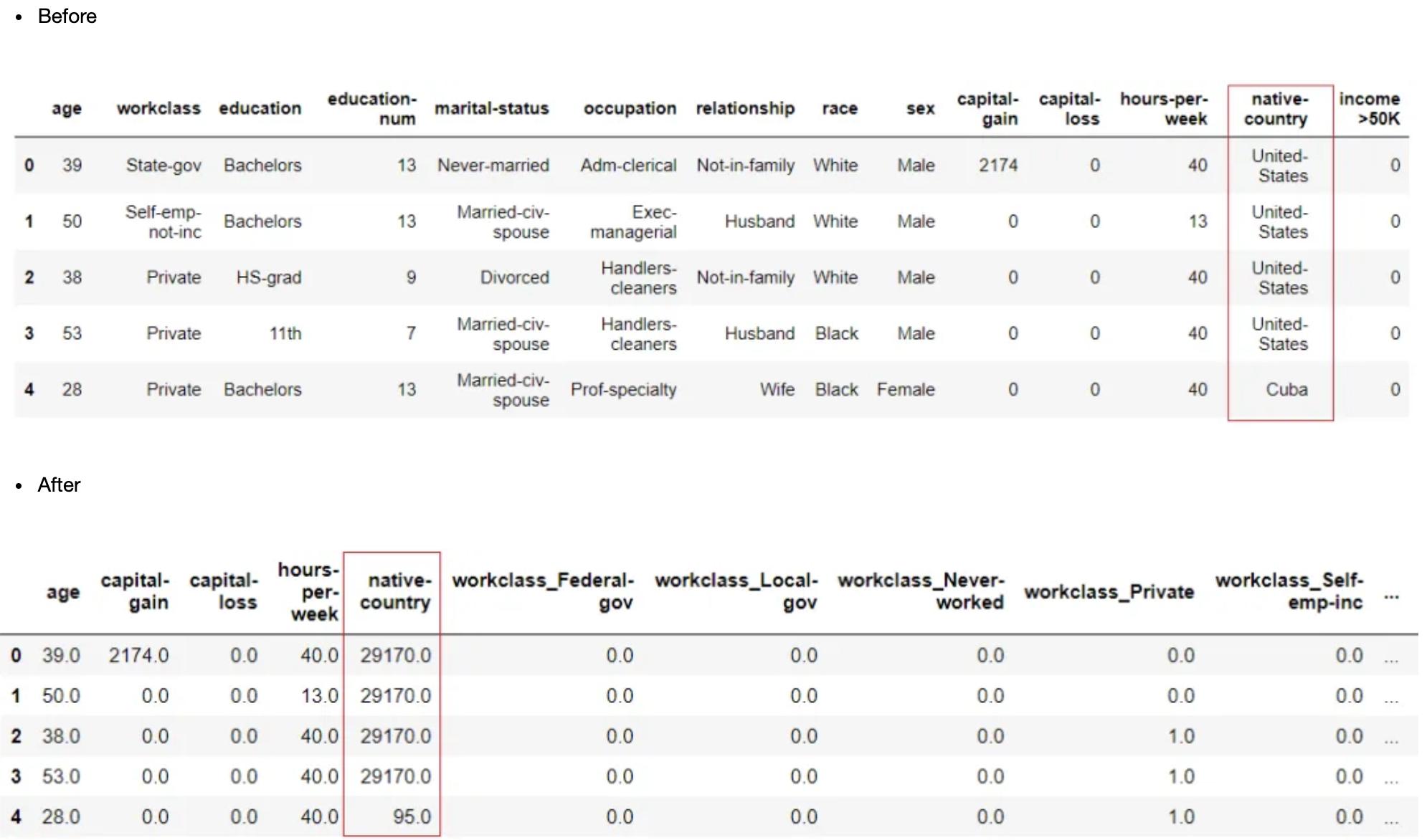

处理未知级别
当未观察到的数据在分类特征上有新的层次,而这些层次在训练模型时是不存在的,这可能会导致训练算法在生成准确预测时出现问题。处理这些数据点的一种方法是将它们重新分配到已知的分类特征级别,即训练数据集中已知的级别。这可以在PyCaret中使用?handle_unknown_categorical?参数来实现,该参数默认设置为True。它支持两种方法“least_frequent”和“most_frequent”,可以在设置中使用未知的分类方法参数进行控制。
# Importing dataset
insurance = read_csv('insurance.csv')
# Importing module and initializing setup
from pycaret.regression import *
'''
handle_unknown_categorical: bool, default = True
当设置为True时,新数据/未显示数据中的未知分类级别将替换为在训练数据中学习到的最频繁或最不频繁级别。
方法是在 unknown_categorical_method 参数下定义的。
unknown_categorical_method: string, default = ‘least_frequent’
用于替换未显示数据中未知类别级别的方法。方法可以设置为“‘least_frequent”或“most_frequent”。
'''
reg1 = setup(data = insurance, target = 'charges', handle_unknown_categorical = True, unknown_categorical_method = 'most_frequent')
数据规范化与转换
数据规范化 (NORMALIZATION)
规范化是机器学习中常用的一种数据准备技术。规范化的目标是重新调整数据集中数值列的值,而不会扭曲值范围中的差异或丢失信息。这可以在PyCaret中使用设置中的?normalize?参数来实现。有几种方法可用于规范化,默认情况下,它使用“zscore”来规范化数据,可以在安装程序中使用normalize_method?参数对其进行更改。
# Importing dataset
pokemon = read_csv('pokemon.csv')
# Importing module and initializing setup
from pycaret.classification import *
'''
normalize: bool, default = False
当设置为True时,使用 normalized_method 参数变换特征空间。
一般来说,线性算法在处理标准化数据时表现更好,但是结果可能会有所不同,
因此建议运行多个实验来评估标准化的好处。
normalize_method: string, default = ‘zscore’
定义用于规范化的方法。默认情况下,normalize方法设置为“zscore”。
标准zscore计算为z=(x–u)/s。其他可用选项包括:
z-score:标准zscore计算为z=(x–u)/s
minmax:分别缩放和转换每个特征,使其在0-1的范围内。
maxabs:分别缩放和转换每个特征,使每个特征的最大绝对值为1.0。它不会转移/集中数据,因此不会破坏任何稀疏性。
robust:根据四分位数范围缩放和转换每个特征。当数据集包含异常值时,robust的转换通常会给出更好的结果。
'''
clf1 = setup(data = pokemon, target = 'Legendary', normalize = True)
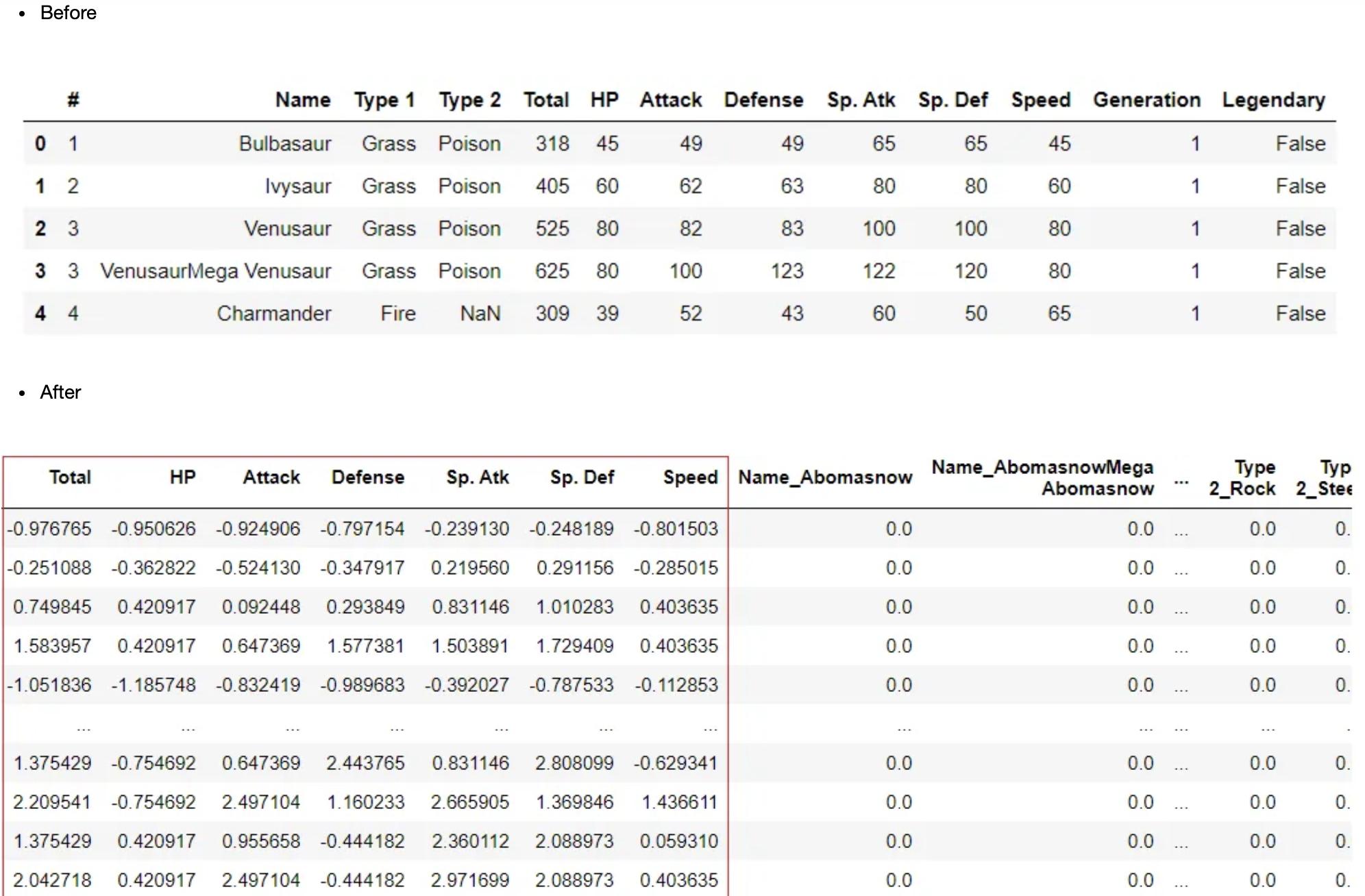

数据转换
当规范化在新的范围内重新调整数据以减少方差的大小影响时,转换是一种更激进的技术。变换改变分布的形状,使得变换后的数据可以用正态或近似正态分布表示。通常,当使用ML算法时,必须对数据进行转换,该算法假定输入数据为正态或高斯分布。这类模型的例子有Logistic回归、线性判别分析(LDA)和高斯朴素贝叶斯。可以使用设置中的转换参数在PyCaret中实现数据转换。有两种方法可用于转换“yeo-johnson”和“quantile”,可通过设置中的转换方法参数定义。
# Importing dataset
pokemon = read_csv('pokemon.csv')
# Importing module and initializing setup
from pycaret.classification import *
'''
transformation: bool, default = False
当设置为True时,将应用幂变换使数据更为正态/高斯型。
这对于建模异方差或其他需要正态性的情况下的相关问题很有用。
通过极大似然估计出了稳定方差和最小化偏度的最优参数。
transformation_method: string, default = ‘yeo-johnson’
定义转换的方法。默认情况下,转换方法设置为“yeo-johnson”。
另一个可用的选项是“quantile”转换。
这两种变换都将特征集变换为遵循类高斯分布或正态分布。
注意,分位数变换器是非线性的,并且可能会扭曲在相同尺度下测量的变量之间的线性相关性。
'''
clf1 = setup(data = pokemon, target = 'Legendary', transformation = True)
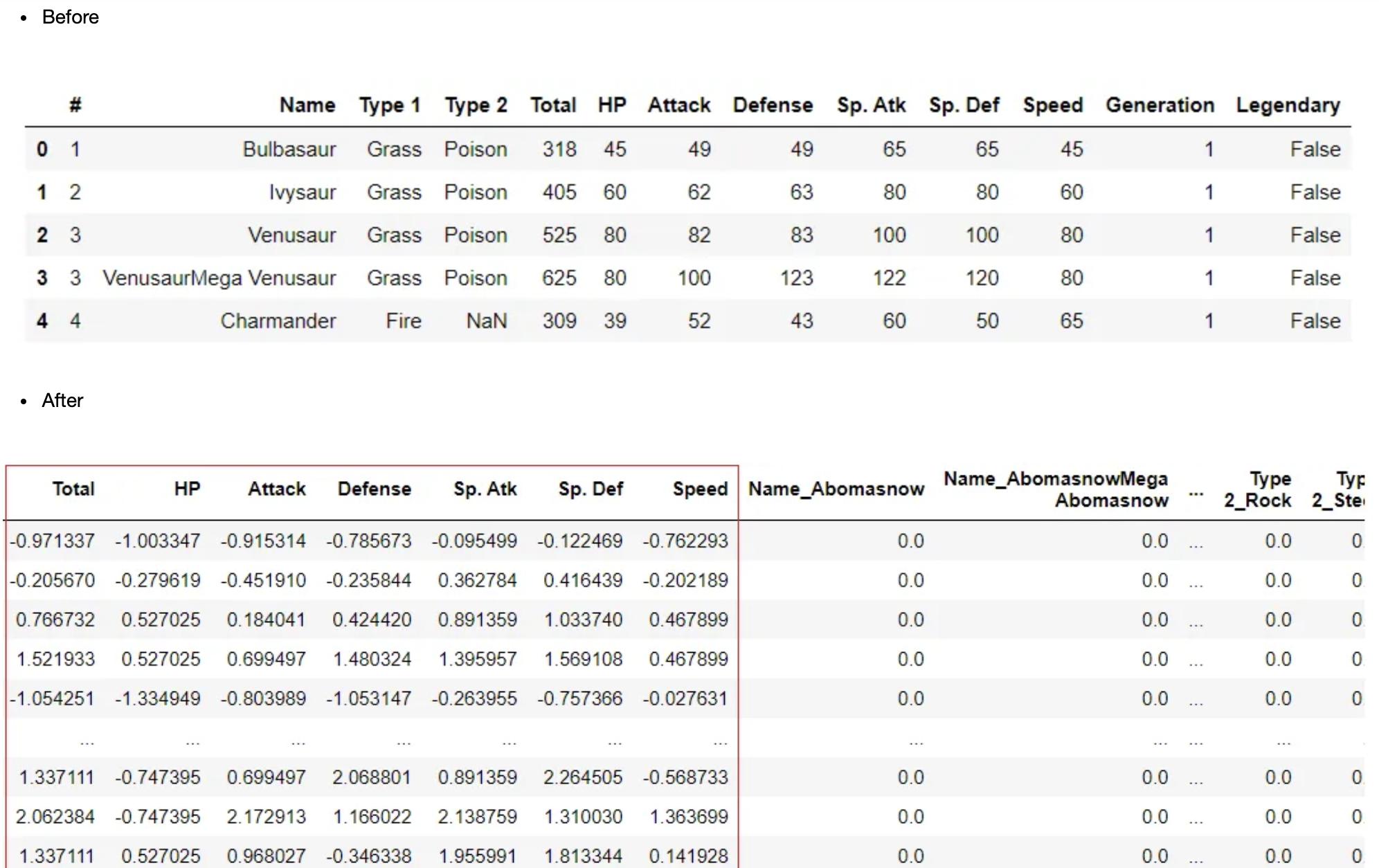

请注意,没有传递任何方法。默认情况下,转换参数使用“yeo-johnson”方法。要更改方法转换,可以在设置中使用方法参数。
目标转换
目标变换类似于数据变换,它用来改变目标变量分布的形状。当使用线性回归或线性判别分析等线性算法进行建模时,必须对目标进行变换。这可以在PyCaret中使用setup中的?transform_target?参数来实现。有两种方法支持目标转换“box-cox”和“yeo-johnson”,可以在设置中使用transform_target_method?参数定义。
# Importing dataset
diamond = read_csv('diamond.csv')
# Importing module and initializing setup
from pycaret.regression import *
'''
transform_target: bool, default = False
当设置为True时,目标变量将使用transform_target_method param中定义的方法进行转换。
目标转换与特征转换分开应用。
transform_target_method: string, default = ‘box-cox’
支持“Box-cox”和“yeo-johnson”方法。Box-Cox要求输入数据严格为正,
而Yeo-Johnson同时支持正数据和负数据,当transform_target_method为“box-cox’”
且目标变量包含负值时,method被内部强制为“yeo-johnson”以避免异常。
'''
reg1 = setup(data = diamond, target = 'Price', transform_target = True)
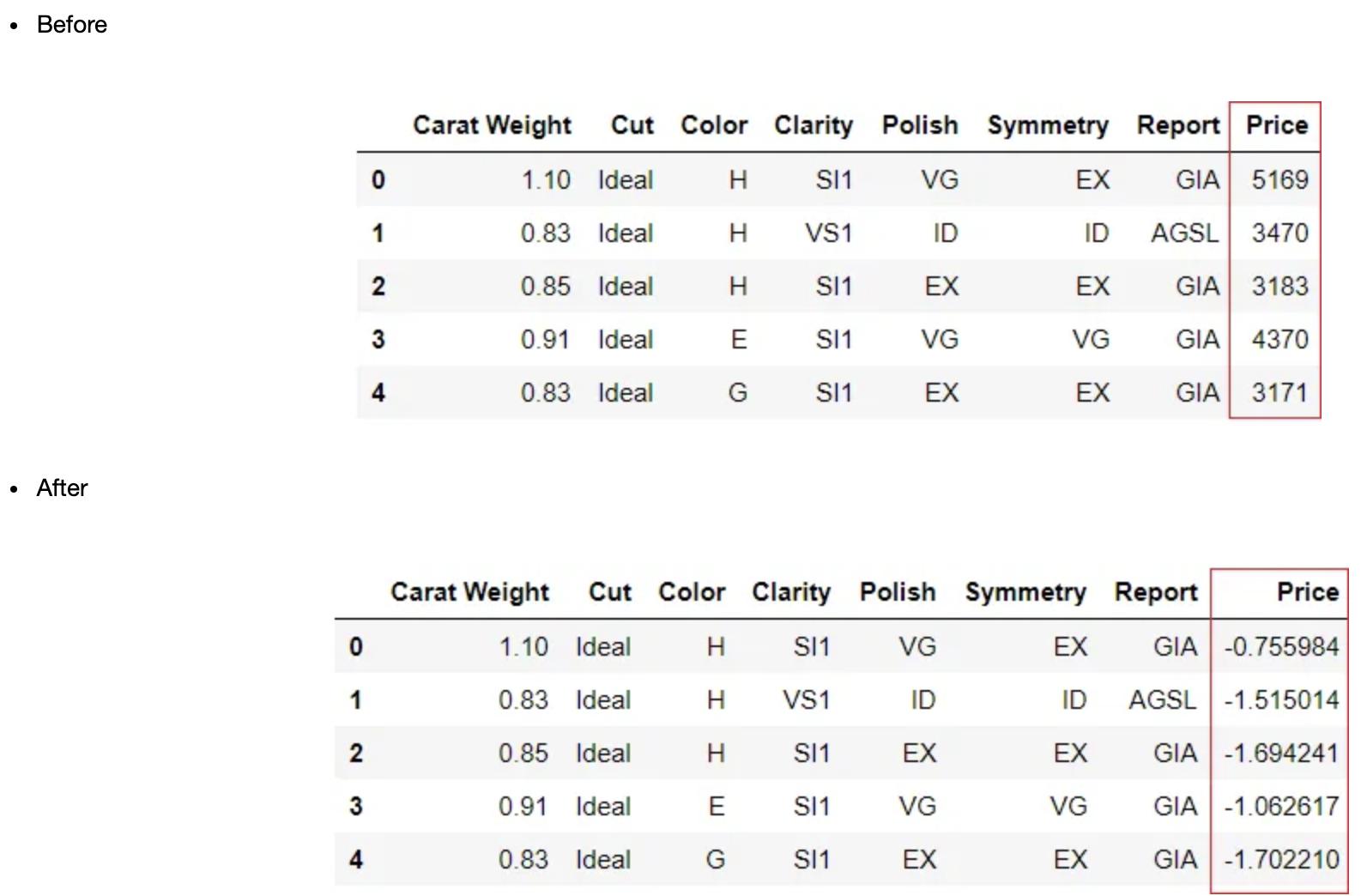

特征工程
在机器学习实验中经常会看到,通过算术运算组合的两个特征在解释数据中的差异时变得比单独使用同一两个特征更为重要。通过现有特征的交互创建新特征称为特征交互。它可以在PyCaret中使用设置中的?feature_interaction?和?feature_ratio?参数来实现。特征交互通过两个变量(a*b)相乘来创建新特征,而特征比率通过计算现有特征的比率(a/b)来创建新特征。
# Importing dataset
insurance = read_csv('insurance.csv')
# Importing module and initializing setup
from pycaret.regression import *
'''
feature_interaction: bool, default = False
当设置为True时,它将通过对数据集中的所有数值变量(包括多项式和三角函数特征(如果创建))进行交互(a*b)来创建新特征。
此功能不可扩展,可能无法在具有较大特征空间的数据集上正常工作。
feature_ratio: bool, default = False
当设置为True时,它将通过计算数据集中所有数值变量的比率(a/b)来创建新特征。
此功能不可扩展,可能无法在具有较大特征空间的数据集上正常工作。
interaction_threshold: bool, default = 0.01
与多项式阈值类似,它通过交互作用来压缩新创建特征的稀疏矩阵。
基于随机森林、AdaBoost和线性相关组合的重要性在定义的阈值百分比范围内的特征保留在数据集中。
其余特征将在进一步处理之前删除。
'''
reg1 = setup(data = insurance, target = 'charges', feature_interaction = True, feature_ratio = True)

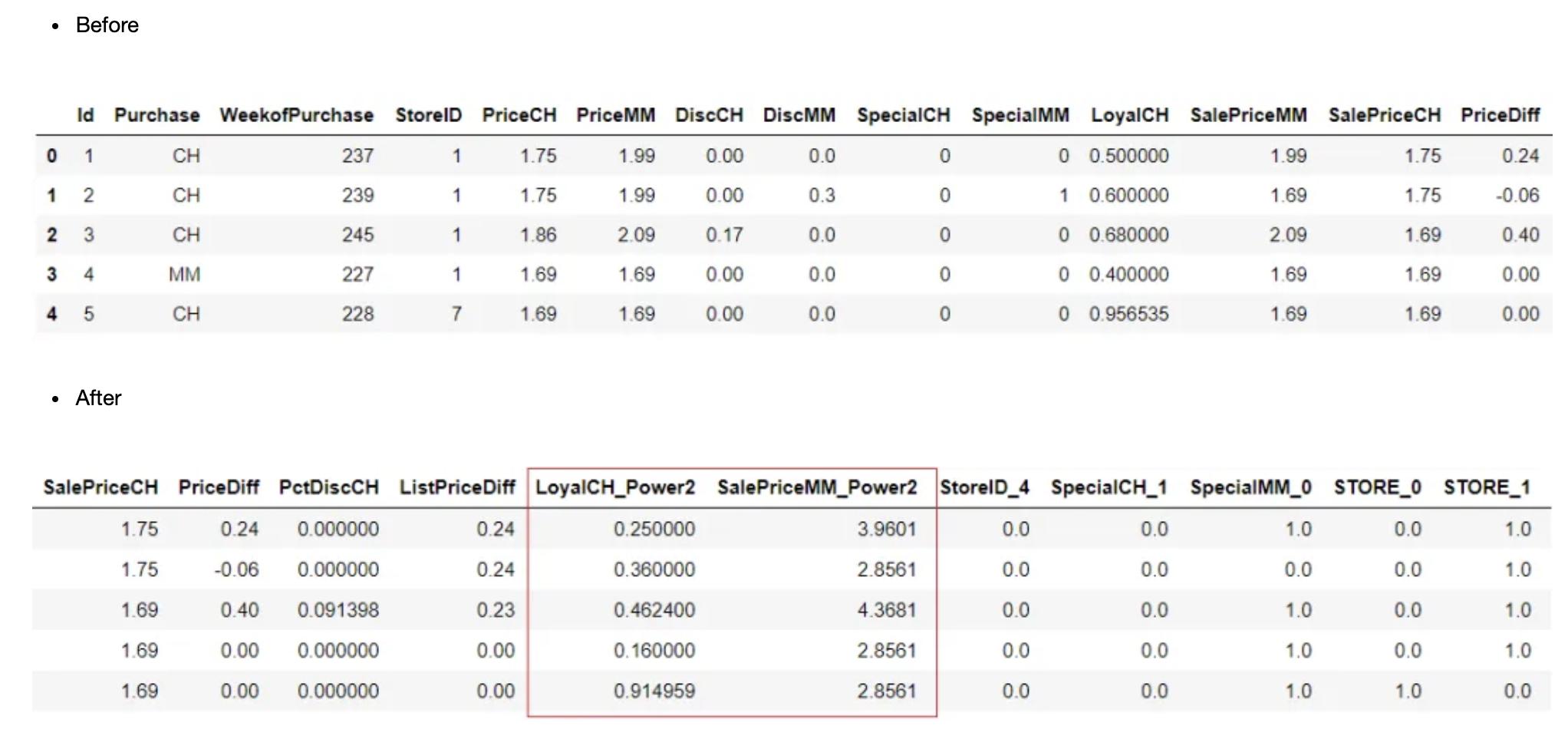
多项式特征
在机器学习实验中,因变量和自变量之间的关系通常被假定为线性关系,但情况并非总是如此。有时因变量和自变量之间的关系更为复杂。创建新的多项式特征有时可能有助于捕获这种关系,否则可能会被忽视。PyCaret可以使用设置中的多项式特征参数从现有特征创建多项式特征。
# Importing dataset
juice = read_csv('juice.csv')
# Importing module and initializing setup
from pycaret.classification import *
'''
polynomial_features: bool, default = False
当设置为True时,将基于数据集中的数字特征中存在的所有多项式组合创建新特征,
并达到多项式参数中定义的程度。
polynomial_degree: int, default = 2
多项式特征的次数。例如,如果输入样本是二维的,并且其形式为[a,b],
则次数为2的多项式特征为:[1,a,b,a^2,ab,b^2]。
polynomial_threshold: float, default = 0.1
它用于压缩多项式和三角特征的稀疏矩阵。
数据集中保留了基于随机森林、AdaBoost和线性相关组合的特征重要性在所定义阈值百分位数以内的多项式和三角特征。
其余特征将在进一步处理之前删除。
'''
clf1 = setup(data = juice, target = 'Purchase', polynomial_features = True)

请注意,新要素是从现有要素空间创建的。为了扩展或压缩多项式特征空间,可以使用基于随机森林、AdaBoost和线性相关组合的特征重要度?polynomial_threshold?参数来滤除非重要多项式特征。polynomial_degree?可用于定义特征创建中要考虑的次数。
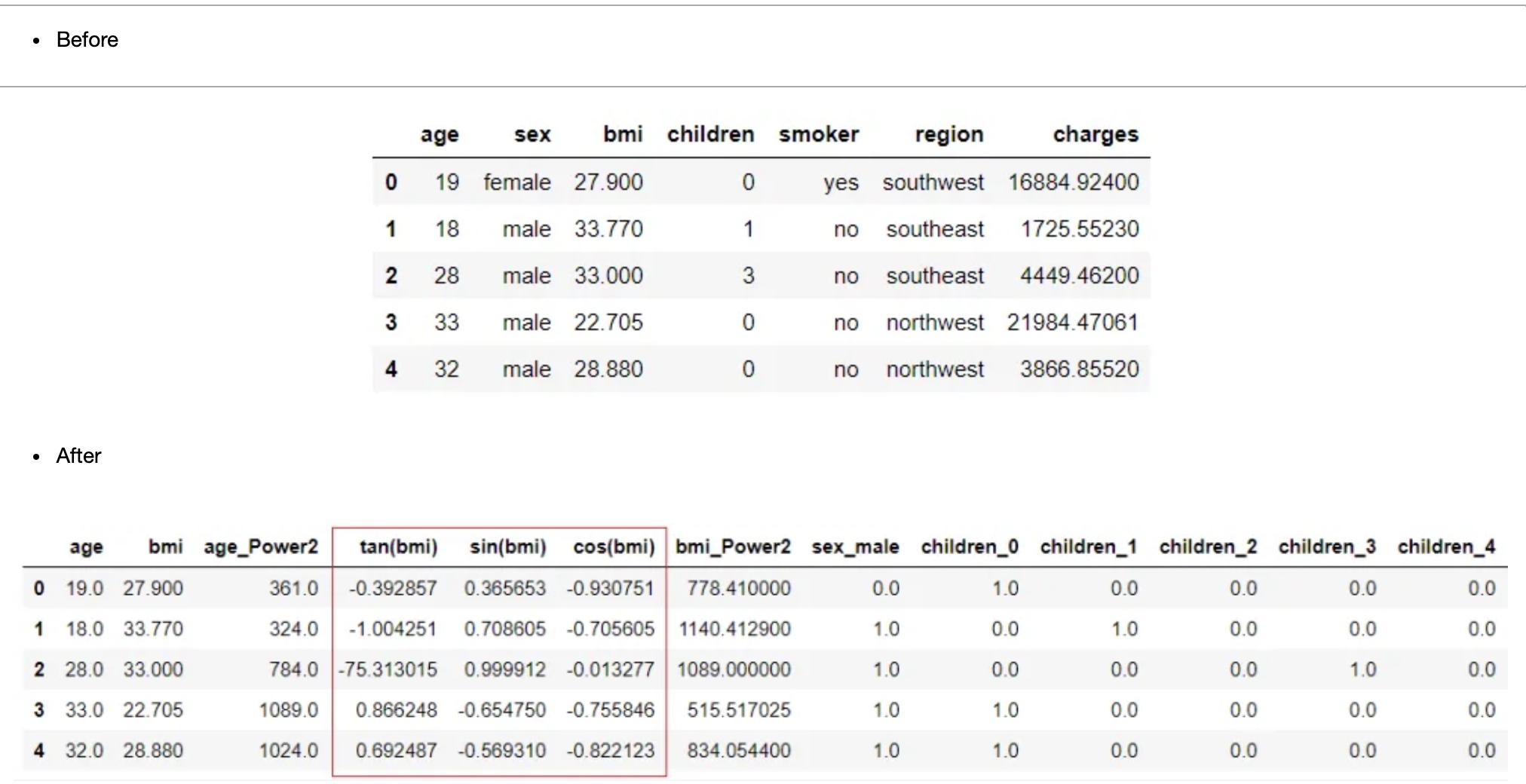
三角特征
与多项式特征类似,PyCaret还允许从现有特征创建新的三角特征。它是在设置中使用三角特征参数实现的。
# Importing dataset
insurance = read_csv('insurance.csv')
# Importing module and initializing setup
from pycaret.regression import *
'''
trigonometry_features: bool, default = False
当设置为True时,将基于数据集中数字特征中存在的所有三角组合创建新特征,
这些三角组合在 polynomial_degree 参数中定义。
'''
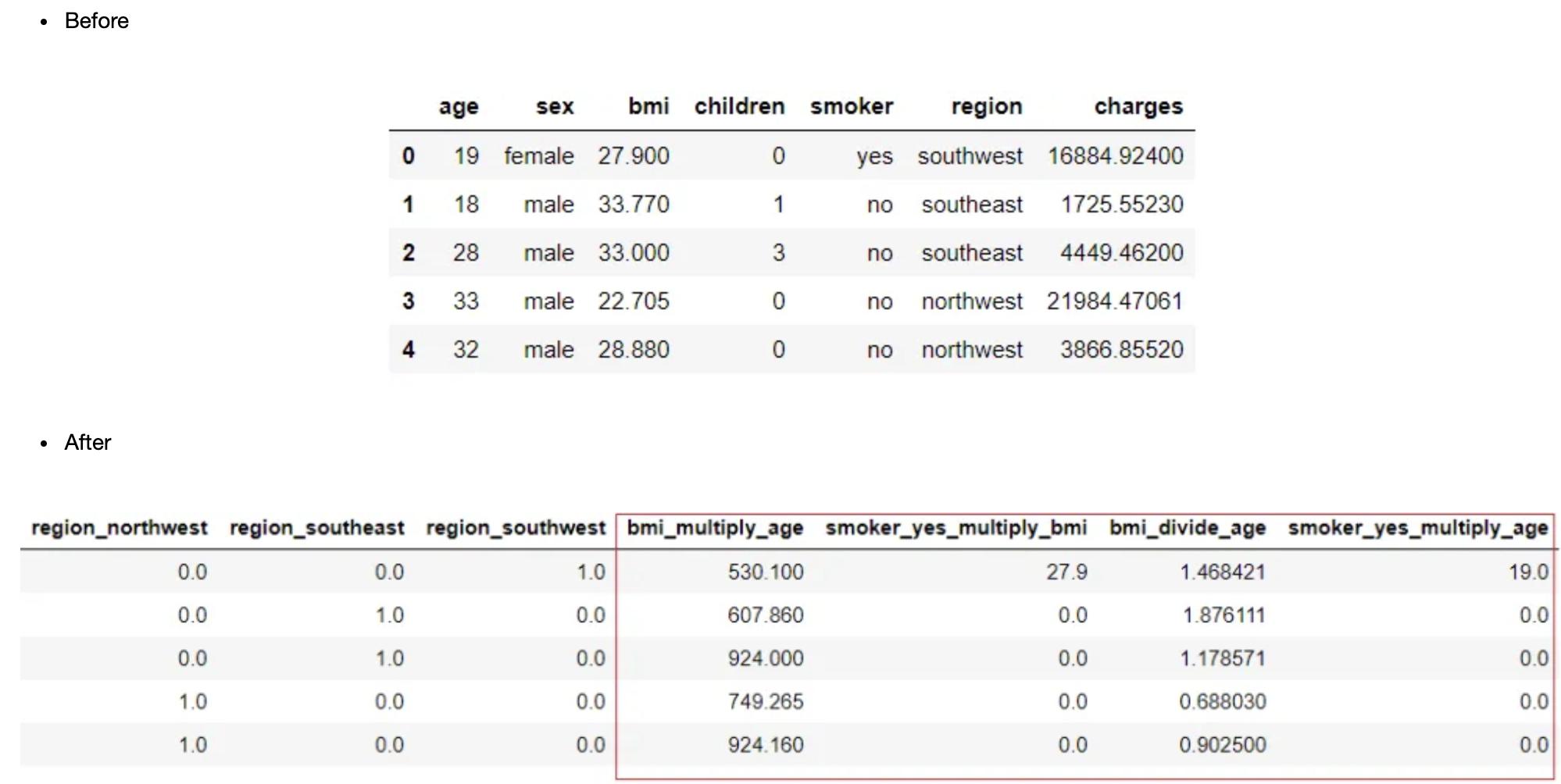
reg1 = setup(data = insurance, target = 'charges', trigonometry_features = True)

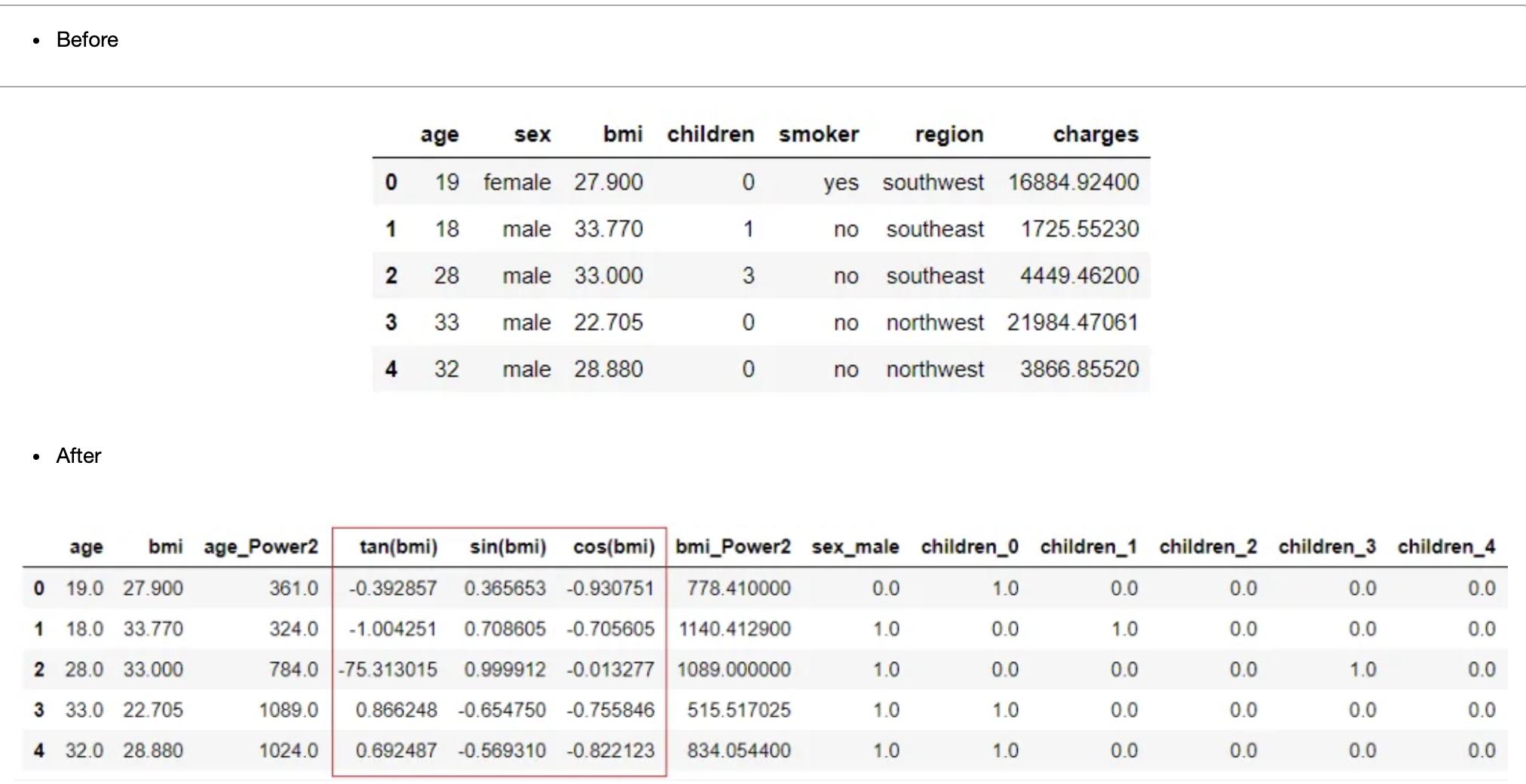

分组特征
当数据集包含以某种方式相互关联的特征时,例如:以某个固定时间间隔记录的特征,则可以使用设置中的组特征参数从现有特征中创建一组此类特征的新统计特征,如平均值、中值、方差和标准差。
# Importing dataset
credit = read_csv('credit.csv')
# Importing module and initializing setup
from pycaret.classification import *
'''
group_features: list or list of list, default = None
当数据集包含具有相关特征的特征时,可以使用分组特征参数进行统计特征提取。
例如,如果数据集具有相互关联的数字特征(即“Col1”、“Col2”、“Col3”),
则可以在分组特征下传递包含列名的列表,以提取统计信息,如平均值、中值、模式和标准差。
group_names: list, default = None
传递 group_features 时,可以将组的名称作为包含字符串的列表传递到 group_names 参数中。
分组名称列表的长度必须等于分组特征的长度。当长度不匹配或未传递名称时,将按顺序命名新特征,如group_1、group_2等。
'''
clf1 = setup(data = credit, target = 'default', group_features = ['BILL_AMT1', 'BILL_AMT2', 'BILL_AMT3', 'BILL_AMT4', 'BILL_AMT5', 'BILL_AMT6'])
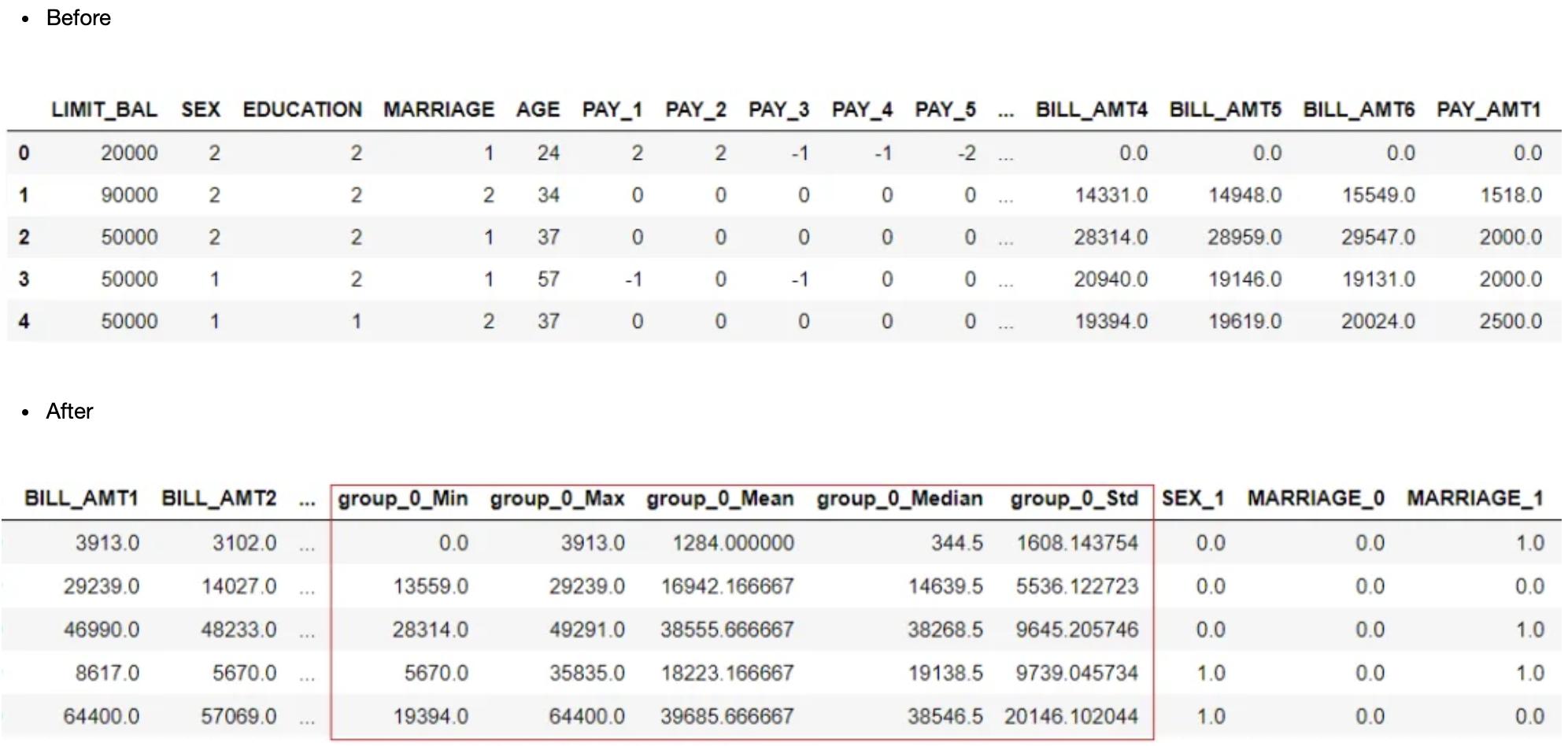

分箱数字特征
特征分箱是一种利用预先定义的箱数将连续变量转化为分类值的方法。当连续特征的唯一值太多或极端值很少超出预期范围时,它是有效的。这样的极值会影响训练后的模型,从而影响模型的预测精度。在PyCaret中,可以使用设置中的?bin_numeric_features?参数将连续的数字特征组合成分箱。PyCaret使用“sturges”规则来确定箱体容器的数量,还使用 K-Means 聚类将连续的数字特征转换为分类特征。
# Importing dataset
income = read_csv('income.csv')
# Importing module and initializing setup
from pycaret.classification import *
'''
bin_numeric_features: list, default = None
当传递一个数字特征列表时,它们将使用K-Means转换为分类特征,
其中每个bin中的值具有1D K-Means簇的最接近中心。
集群的数量是根据“sturges”方法确定的。
它只适用于高斯数据,并且低估了大型非高斯数据集的存储单元数。
'''
clf1 = setup(data = income, target = 'income >50K', bin_numeric_features = ['age'])
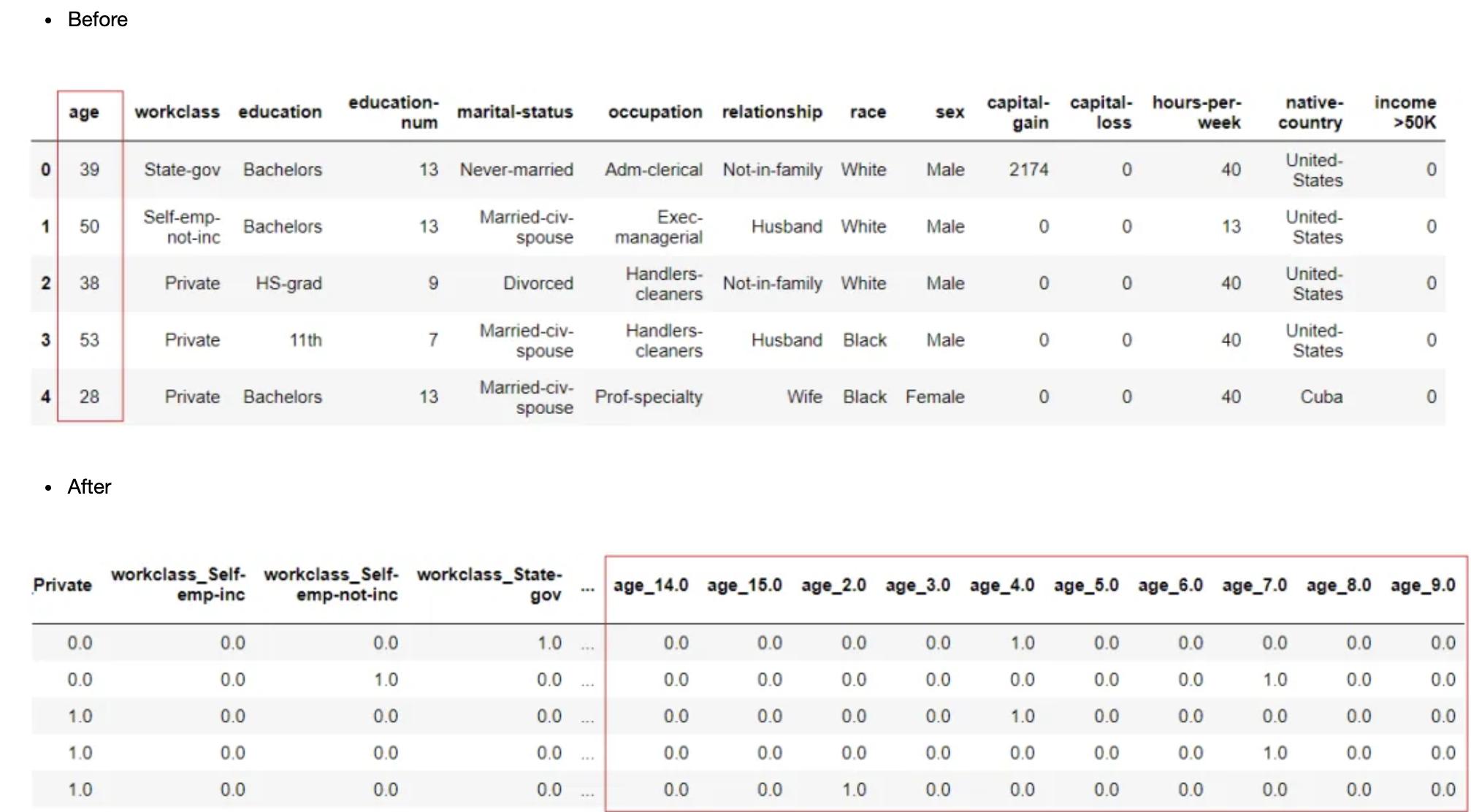

合并稀有级别
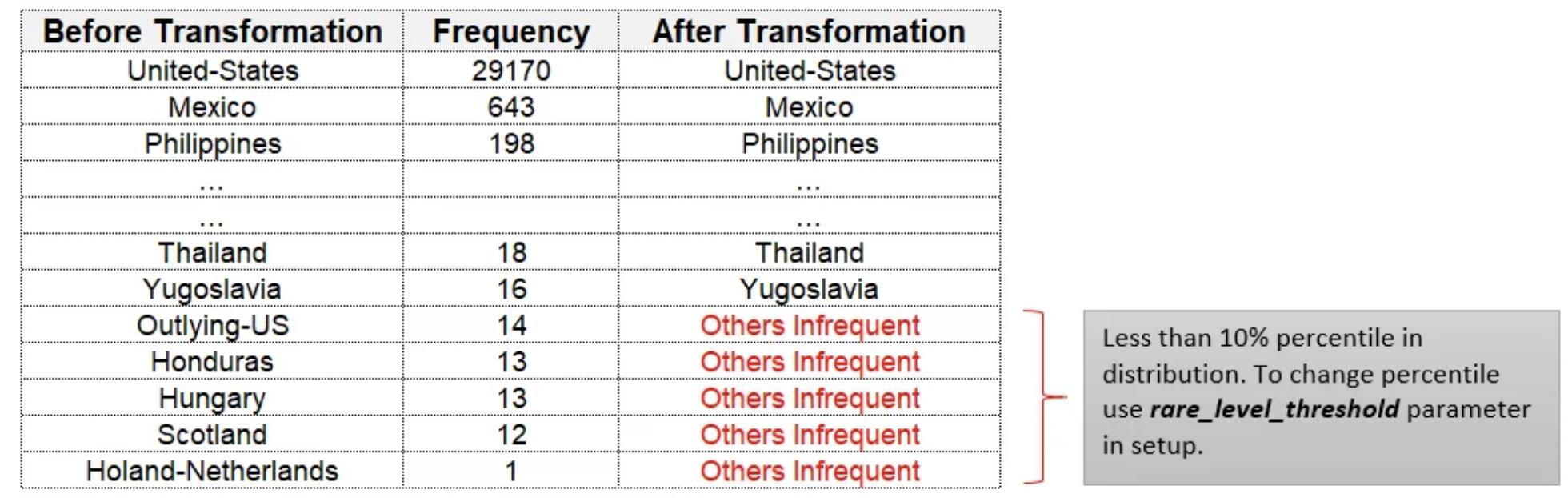
有时,一个数据集可以有一个分类特征(或多个分类特征),具有非常高的级别(即高基数特征)。如果这样的特征(或特征)被编码成数值,那么得到的矩阵就是一个稀疏矩阵。这不仅使实验因特征数目和数据集大小的增加而变慢,而且在实验中引入了噪声。稀疏矩阵可以通过合并具有高基数的特征(或特征)中的罕见级别来避免。这可以在PyCaret中使用设置中的?combine_rare_levels?参数来实现。
# Importing dataset
income = read_csv('income.csv')
# Importing module and initializing setup
from pycaret.classification import *
'''
combine_rare_levels: bool, default = False
如果设置为True,则在 rare_level_threshold 参数中定义的阈值以下的分类特征中的所有级别将合并为一个级别。
必须至少有两个级别低于阈值才能生效。 rare_level_threshold 代表能级频率的百分位分布。
一般来说,这项技术是用来限制由类别特征中的大量级别引起的稀疏矩阵。
rare_level_threshold: float, default = 0.1
百分位分布,低于百分位分布的稀有类别合并在一起。只有当“combine_rare_levels”设置为“True”时才生效。
'''
clf1 = setup(data = income, target = 'income >50K', combine_rare_levels = True)
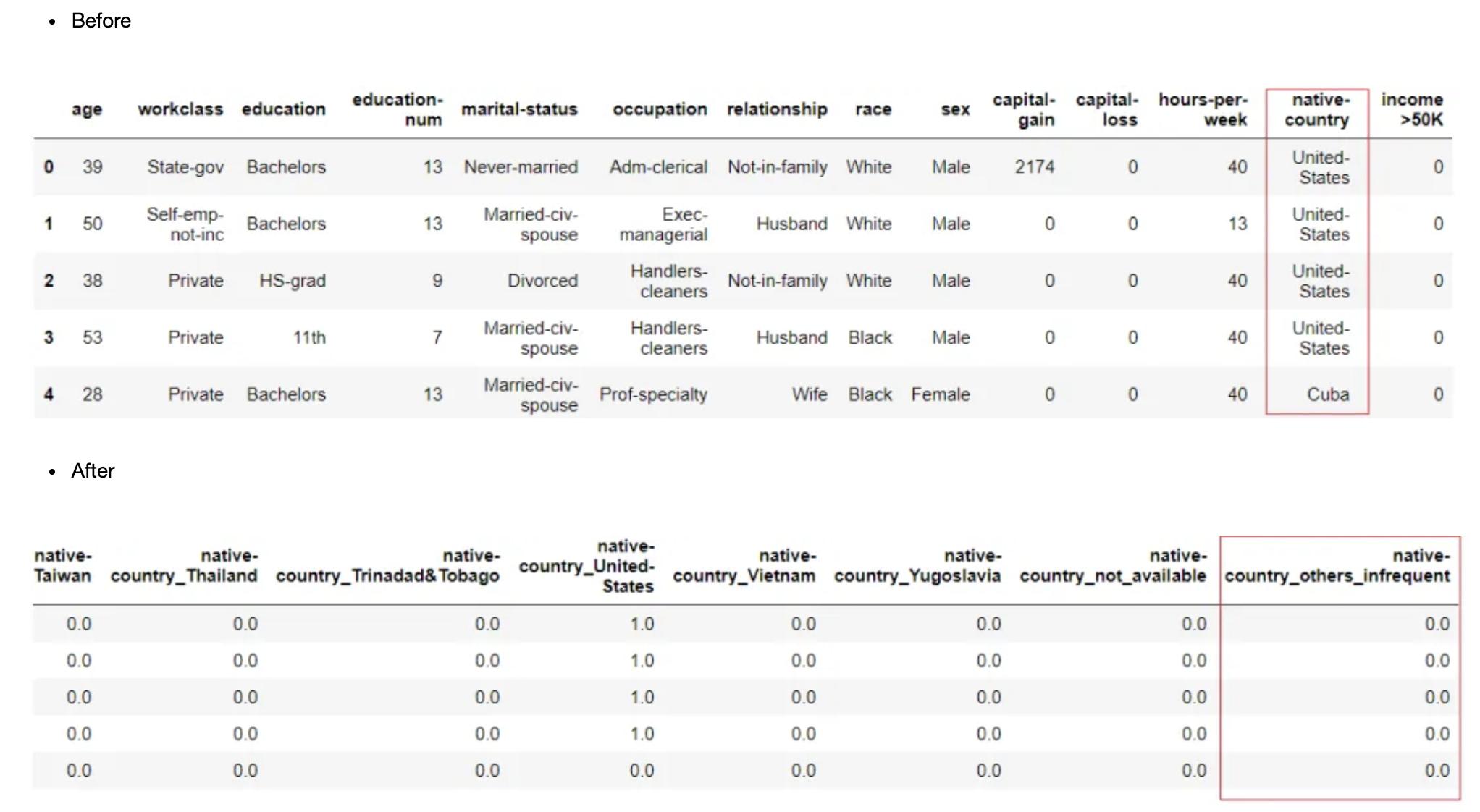

- 合并后效果

特征选择
特征重要性是用于在数据集中选择在预测目标变量方面贡献最大的特征的过程。使用选定的特征而不是所有特征可以减少过度拟合的风险,提高准确性,并减少训练时间。在PyCaret中,这可以使用?feature_selection?参数来实现。它使用多种监督特征选择技术的组合来选择对建模最重要的特征子集。子集的大小可以通过设置中的?feature_selection_threshold?参数来控制。
# Importing dataset
diabetes = read_csv('diabetes.csv')
# Importing module and initializing setup
from pycaret.regression import *
'''
feature_selection: bool, default = False
当设置为True时,使用各种排列重要性技术(包括随机林、Adaboost和与目标变量的线性相关)的组合来选择特征子集。
子集的大小取决于 feature_selection_param 参数。为了提高建模效率,通常采用约束特征空间的方法。
当使用 polynomial_features 和 feature_interaction 时,强烈建议使用较低的值定义 feature_selection_threshold 参数。
feature_selection_threshold: float, default = 0.8
用于特征选择的阈值(包括新创建的多项式特征)。值越大,特征空间越大。
建议在使用 polynomial_features 和 feature_interaction 的情况下,
使用不同的 feature_selection_threshold 进行多次试验。
设置一个非常低的值可能是有效的,但可能会导致欠拟合。
'''
clf1 = setup(data = diabetes, target = 'Class variable', feature_selection = True)
消除多重共线性
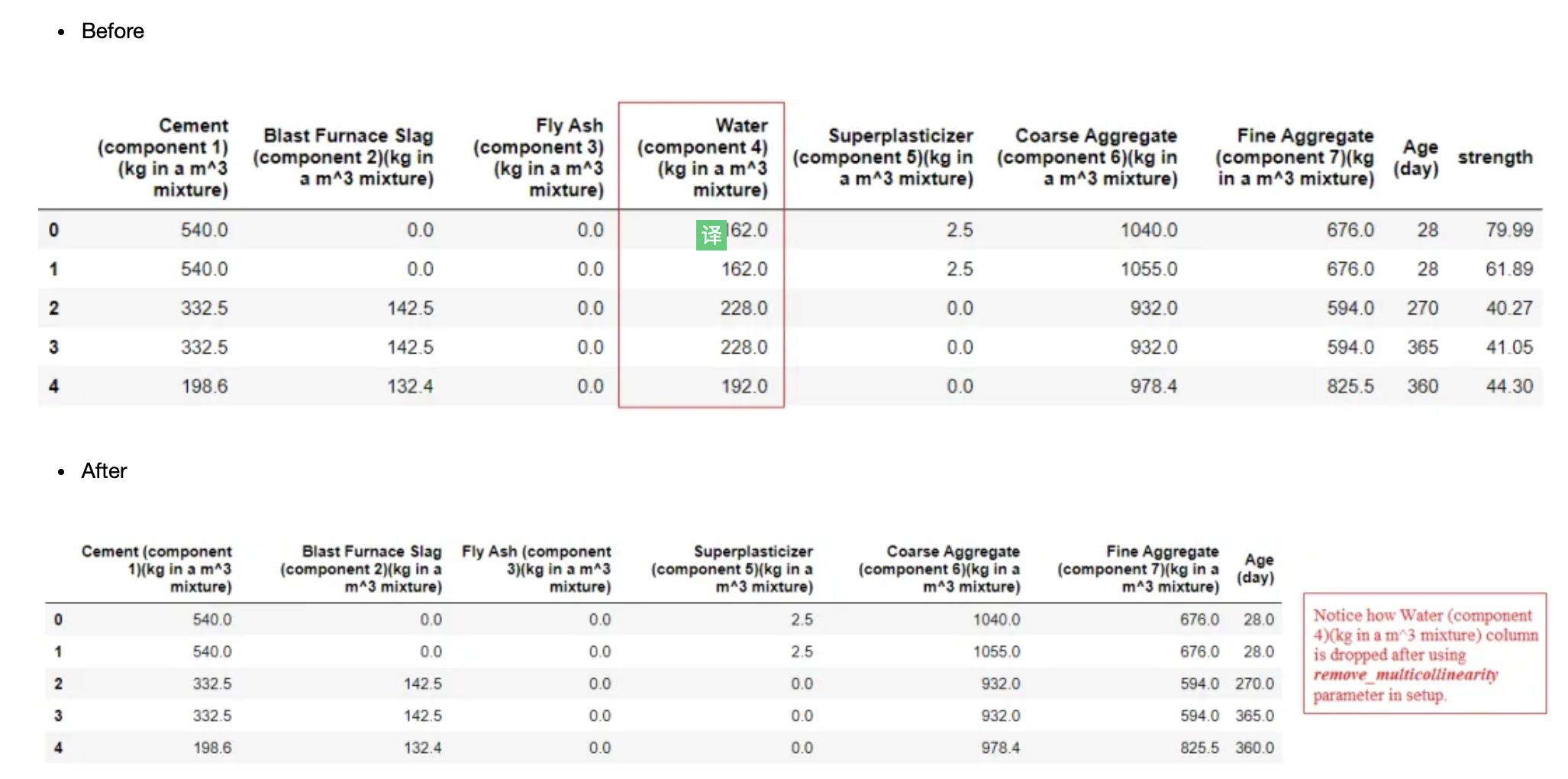
多重共线性(也称为共线性)是指数据集中的一个特征变量与同一数据集中的另一个特征变量高度线性相关的现象。多重共线性增加了系数的方差,从而使线性模型的系数变得不稳定和有噪声。处理多重共线性的一种方法是去掉彼此高度相关的两个特征之一。这可以在PyCaret中使用setup中的remove_multicollinearcity?参数来实现。
# Importing dataset
concrete = read_csv('concrete.csv')
# Importing module and initializing setup
from pycaret.regression import *
'''
remove_multicollinearity: bool, default = False
当设置为True时,将丢弃相关性高于多重共线性阈值参数下定义的阈值的变量。
当两个特征高度相关时,与目标变量相关性较小的特征将被删除。
multicollinearity_threshold: float, default = 0.9
用于删除相关特征的阈值。只有当“remove_multicollinearity”设置为“True”时才生效。
'''
reg1 = setup(data = concrete, target = 'strength', remove_multicollinearity = True, multicollinearity_threshold = 0.6)

主成分分析
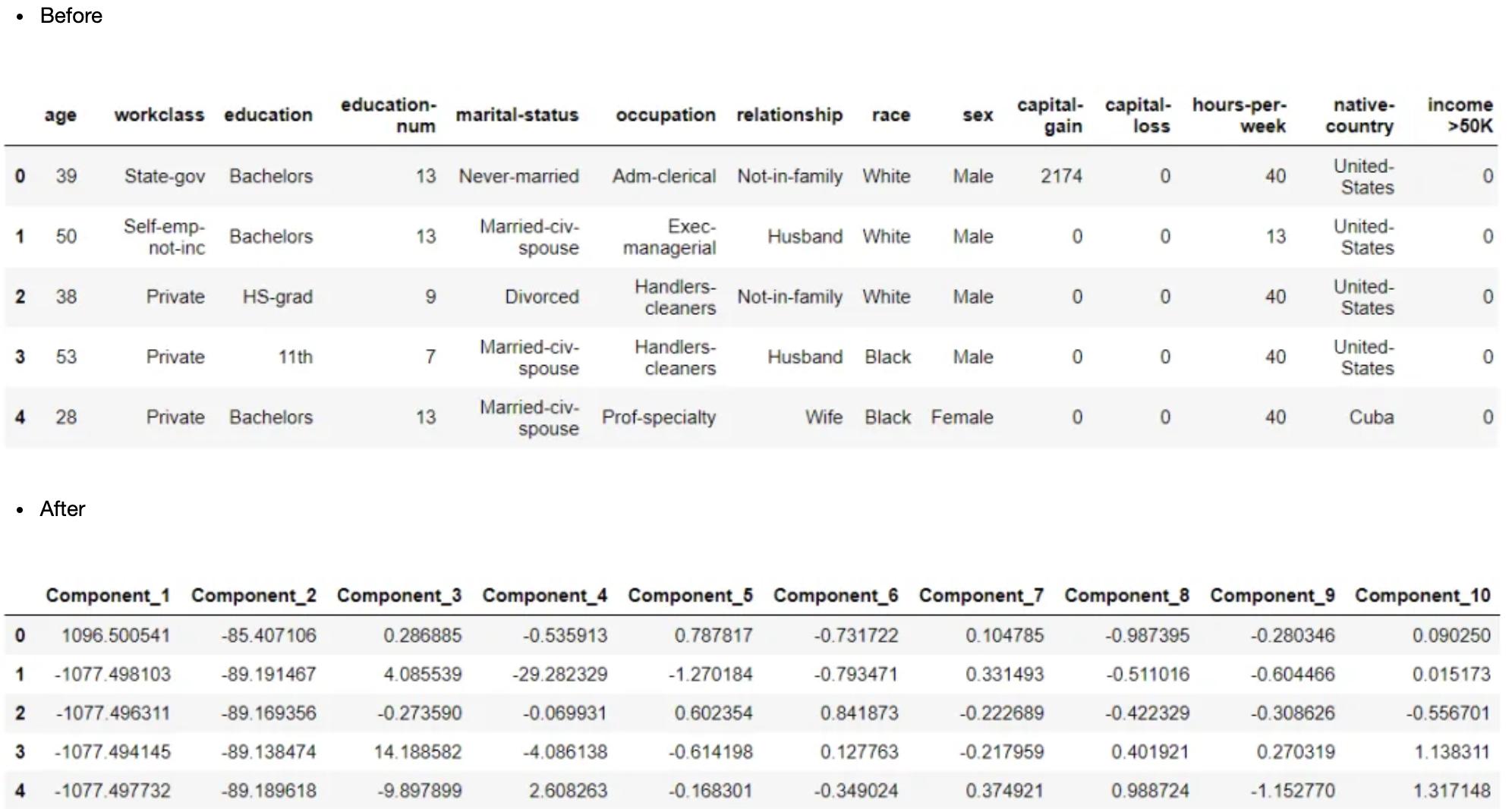
主成分分析(PCA)是机器学习中用来降低数据维数的一种无监督技术。它通过识别一个子空间来压缩特征空间,该子空间捕获了完整特征矩阵中的大部分信息。它将原始特征空间投影到低维空间中。这可以在PyCaret中使用设置中的?pca?参数来实现。
# Importing dataset
income = read_csv('income.csv')
# Importing module and initializing setup
from pycaret.classification import *
'''
pca: bool, default = False
如果设置为True,则使用 `pca_method` 参数中定义的方法将数据投影到低维空间中。
在有监督学习中,pca通常在处理高特征空间时执行,而内存是一个约束条件。
请注意,并非所有数据集都可以使用线性PCA技术有效地分解,并且应用PCA可能会导致信息丢失。
因此,建议使用不同的`pca_method` 进行多个实验来评估影响。
pca_method: string, default = ‘linear’
“linear”方法使用奇异值分解来执行线性降维。其他可用选项包括:
kernel:利用RVF核进行降维。
incremental :当要分解的数据集太大而无法放入内存时,替换“线性”主成分分析
pca_components: int/float, default = 0.99
要保留的组件数。如果 pca_components 是一个浮点数,则将其视为信息保留的目标百分比。
当 pca_components 是整数时,它被视为要保留的特征数。
pca_components 必须严格小于数据集中的原始特征数。
'''
clf1 = setup(data = income, target = 'income >50K', pca = True, pca_components = 10)

忽略低方差
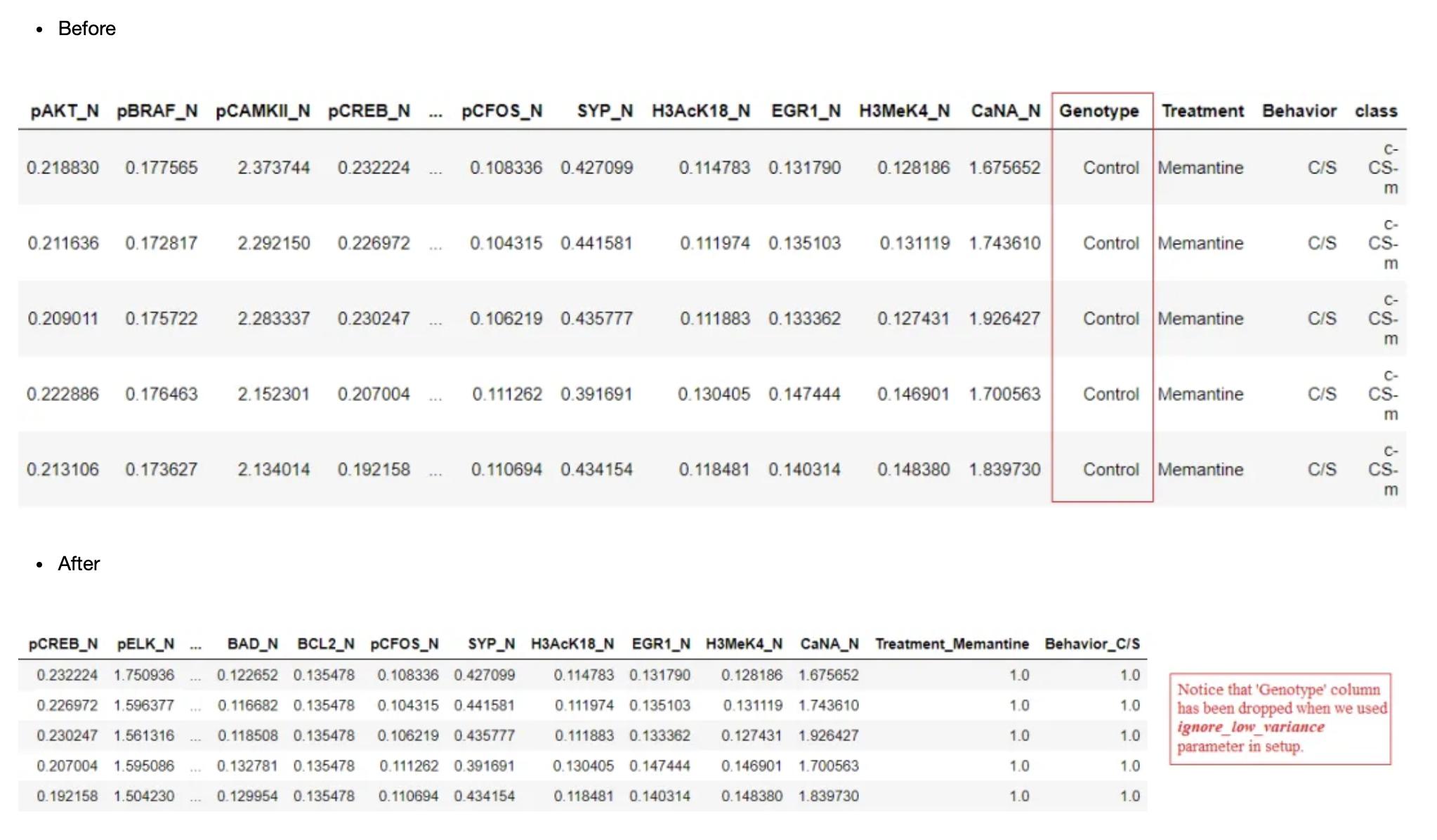
有时,一个数据集可能具有多个级别的分类特征,其中这些级别的分布是倾斜的,一个级别可能支配其他级别。这意味着这种特性提供的信息没有太大的变化。对于一个ML模型,这样的特性可能不会增加很多信息,因此在建模时可以忽略。这可以在PyCaret中使用设置中的?ignore_low_variance?参数来实现。要将特征视为低方差特征,必须满足以下两个条件。
- 特征/样本大小中唯一值的计数<10%
- 最常见值计数/第二常见值计数>20次。
# Importing dataset
mice = read_csv('mice.csv')
# Filter the column to demonstrate example
mice = mice[mice['Genotype']== 'Control']
# Importing module and initializing setup
from pycaret.classification import *
'''
ignore_low_variance: bool, default = False
当设置为True时,将从数据集中移除具有统计上不显著的差异的所有分类特征。
使用唯一值与样本数的比率以及最常用值与第二常用值的频率的比率来计算方差。
'''
clf1 = setup(data = mice, target = 'class', ignore_low_variance = True)

无监督
创建聚类
使用数据中的现有特性创建聚类是一种无监督的ML技术,用于设计和创建新特征。利用 Calinski-Harabasz 和 Silhouette 准则相结合的迭代方法确定聚类数。每个具有原始特征的数据点被分配给一个集群。然后,将指定的簇标签用作预测目标变量的新特征。这可以在PyCaret中使用setup中create_clusters?参数来实现。
# Importing dataset
insurance = read_csv('insurance.csv')
# Importing module and initializing setup
from pycaret.regression import *
'''
create_clusters: bool, default = False
当设置为True时,将创建一个附加特征,其中每个实例都分配给一个聚类。使用Calinski-Harabasz和 Silhouette 准则的组合来确定簇的数量。
cluster_iter: int, default = 20
用于创建聚类的迭代次数。每次迭代都表示聚类大小。仅当 create_clusters 参数设置为 True 时生效。
'''
reg1 = setup(data = insurance, target = 'charges', create_clusters = True)
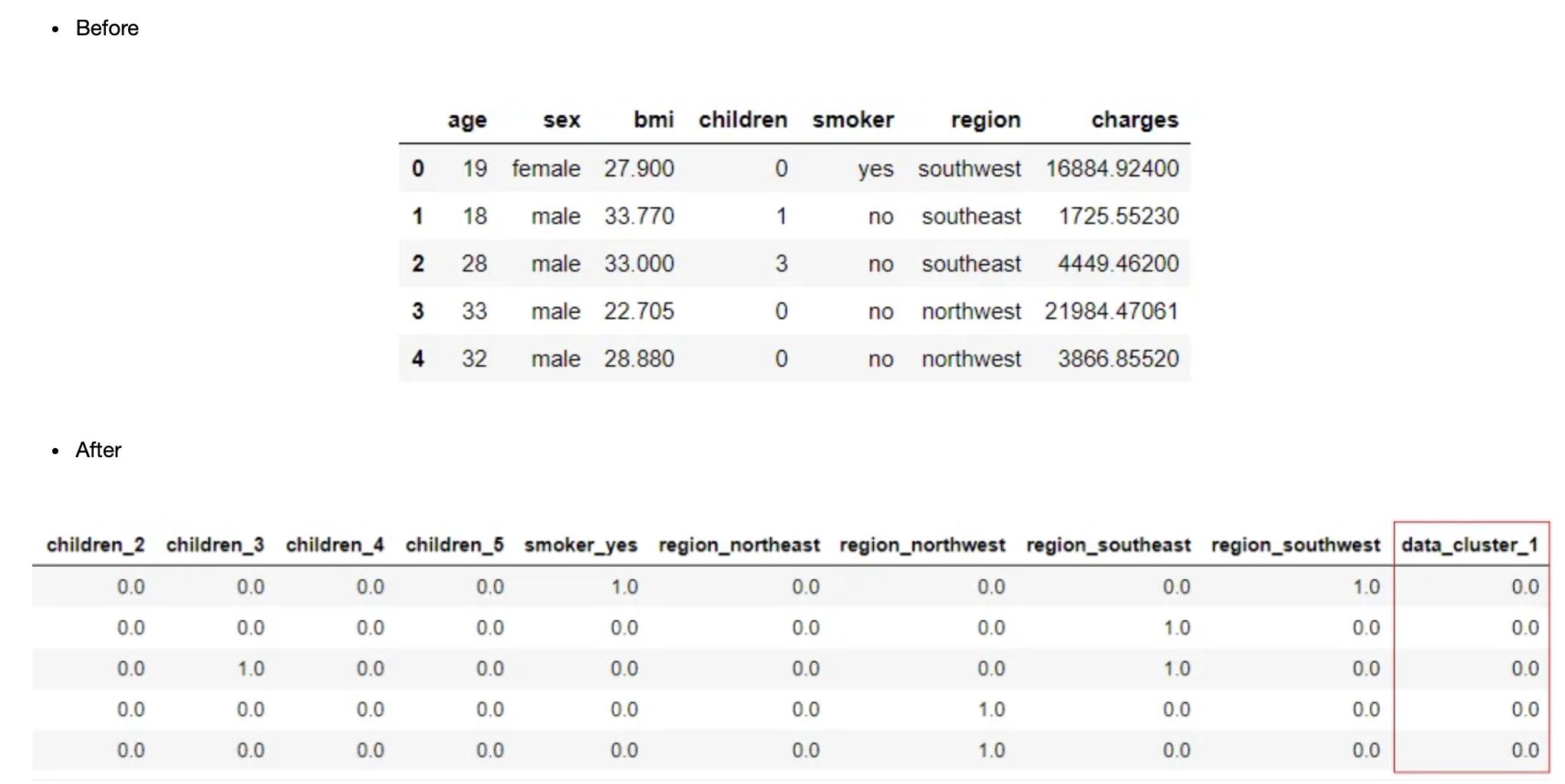

删除异常值
PyCaret中的删除异常值函数允许您在训练模型之前识别并从数据集中删除异常值。利用奇异值分解技术,通过PCA线性降维识别异常值。它可以通过设置中的?remove_outliers?参数来实现。通过?outliers_threshold?参数控制异常值的比例。
# Importing dataset
insurance = read_csv('insurance.csv')
# Importing module and initializing setup
from pycaret.regression import *
'''
remove_outliers: bool, default = False
当设置为 True 时,使用PCA线性降维和奇异值分解技术去除训练数据中的异常值。
outliers_threshold: float, default = 0.05
数据集中离群值的百分比/比例可以使用离群值阈值参数定义。
默认情况下,使用0.05,这意味着分布尾部每侧的0.025个值将从训练数据中删除。
'''
reg1 = setup(data = insurance, target = 'charges', remove_outliers = True)


模型训练
比较模型
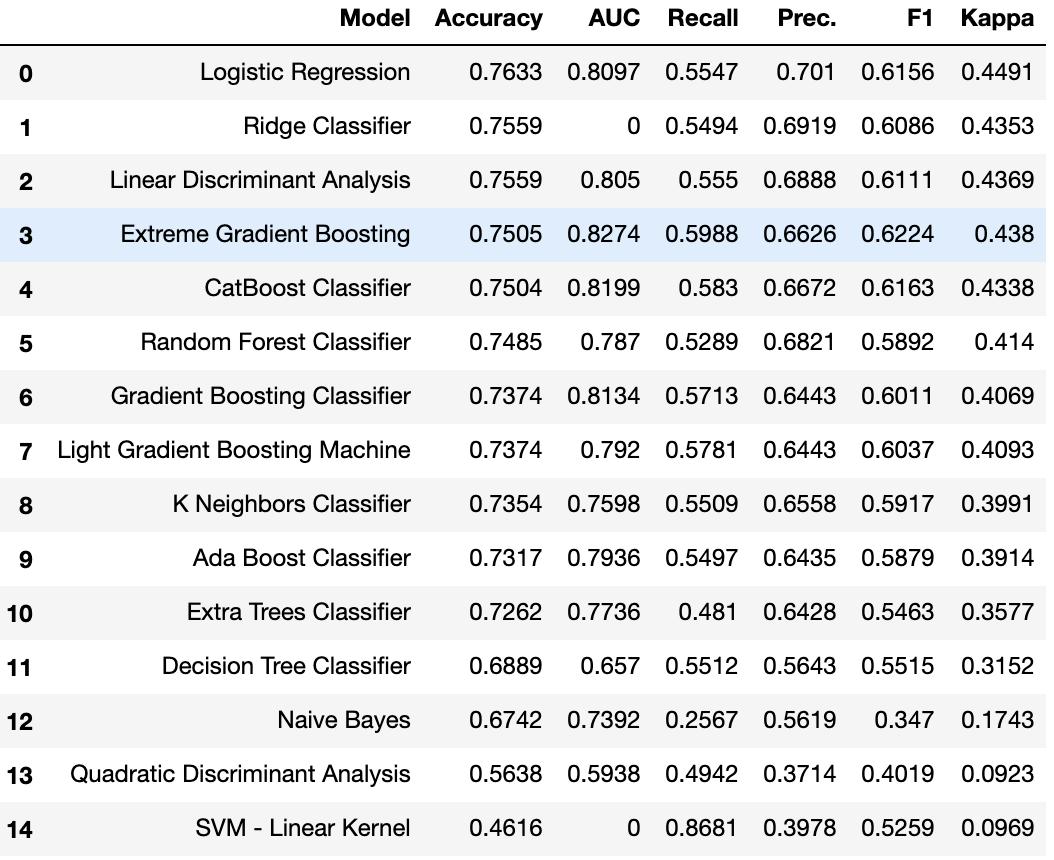
这是在有监督的机器学习实验(分类或回归)中建议的第一步。此功能训练模型库中的所有模型,并使用k倍交叉验证(默认10倍)比较通用评估指标。使用的评估指标是:
- 分类:Accuracy(精确度),AUC,Recall(召回率),Precision(准确度),F1,Kappa
- 回归:MAE,MSE,RMSE,R2,RMSLE,MAPE
函数的输出是一个表格,显示所有模型在k倍交叉中的平均得分。可使用“compare_models”函数中的“fold”参数定义交叉次数。默认情况下,交叉设置为10。表按选择的度量进行排序(从高到低),可以使用sort参数定义。默认情况下,对于分类实验,表按 Accuracy (精确度)排序;对于回归实验,表按R2排序。某些模型由于运行时间较长而无法进行比较。为了绕过此预防措施,可以将turbo参数设置为False。
此函数仅在pycaret.classification和pycaret.regression模块中可用。
分类示例
# Importing dataset
diabetes = read_csv('diabetes.csv')
# Importing module and initializing setup
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# comparing all models
compare_models()

回归示例
# Importing dataset
boston = read_csv('boston.csv')
# Importing module and initializing setup
from pycaret.regression import *
reg1 = setup(data = boston, target = 'medv')
# comparing all models
compare_models()


创建模型
在PyCaret的任何模块中创建模型就像编写create_model一样简单。它仅接受一个参数,即作为字符串输入传递的模型名称。此函数返回具有k倍交叉验证分数和训练有素的模型对象的表格。
在任何模块中创建模型都和编写 create_model 一样简单。它只接受一个参数,即模型缩写为字符串。对于有监督的模块(分类和回归),此函数返回一个表,其中包含经过k倍交叉验证的常用评估指标得分以及经过训练的模型对象。对于无监督的模块(聚类、异常检测、自然语言处理和关联规则挖掘),此函数只返回经过训练的模型对象。使用的评估指标包括:
- 分类:Accuracy, AUC, Recall, Precision, F1, Kappa
- 回归:MAE、MSE、RMSE、R2、RMSLE、MAPE
可以使用create_model函数中的fold参数定义交叉次数。默认情况下,交叉设置为10。默认情况下,所有度量都四舍五入到4位小数,可以使用create_model 中的 round 参数进行更改。虽然有一个单独的函数来集成训练模型,但是有一个快速的方法可以集成模型,同时在create_model函数中使用集成参数和方法参数来创建。
adaboost = create_model('ada')
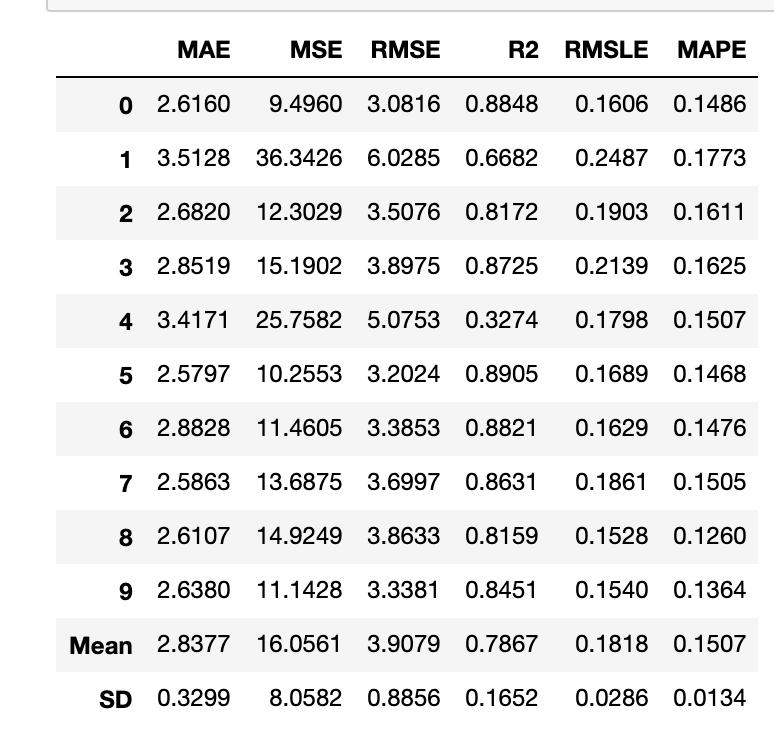

变量“ adaboost”存储一个由create_model函数返回的经过训练的模型对象,该对象是scikit-learn评估器。可以通过在变量后使用点(.)来访问训练对象的原始属性。请参见下面的示例。
特别提醒:ret具有60多个开源即用型(ready-to-use)算法。






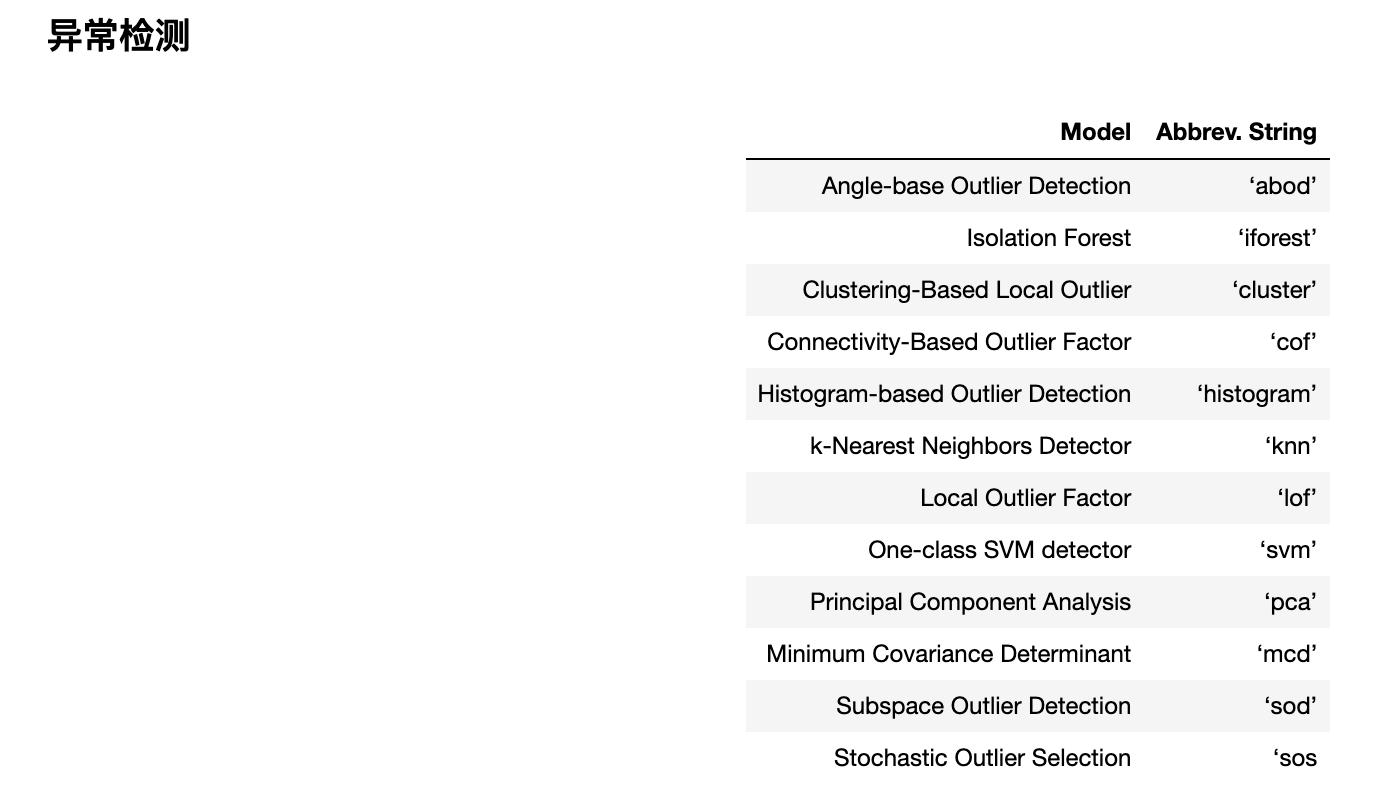

关联规则挖掘
# Importing dataset
france = read_csv('france.csv')
# Importing module and initializing setup
from pycaret.arules import *
arule1 = setup(data = france, transaction_id = 'InvoiceNo', item_id = 'Description')
# creating Association Rule model
mod1 = create_model(metric = 'confidence')


调优模型
在任何模块中调整机器学习模型的超参数都和编写 tune_model 一样简单。它只接受一个强制参数,即模型缩写为字符串。因为优化模型的超参数需要一个目标函数,在分类或回归等有监督的实验中,该目标函数自动链接到目标变量。然而,对于无监督的实验,如聚类、异常检测和自然语言处理,PyCaret允许您通过在 tune_model 中使用受监督的目标参数指定受监督的目标变量来定义自定义目标函数(参见下面的示例)。对于监督学习,此函数返回一个表,其中包含经过k倍交叉验证的常用评估指标得分以及训练的模型对象。对于无监督学习,此函数只返回训练过的模型对象。用于监督学习的评估指标包括:
- 分类: Accuracy, AUC, Recall, Precision, F1, Kappa
- 回归: MAE, MSE, RMSE, R2, RMSLE, MAPE
可使用 tune_model 函数中的 fold 参数定义交叉次数。默认情况下,交叉设置为10。所有度量都四舍五入到四位小数,可以使用 round 参数进行更改。PyCaret中的 tune_model 函数是预定义搜索空间的随机网格搜索,因此它依赖于搜索空间的迭代次数。默认情况下,此函数在搜索空间上执行10次随机迭代,可使用 tune_model 中的 n_iter 参数进行更改。增加 n_iter 参数可能会增加训练时间,但往往会导致模型高度优化。可以使用优化参数定义要优化的度量。默认情况下,回归任务将优化 R2,分类任务将优化 Accuracy。
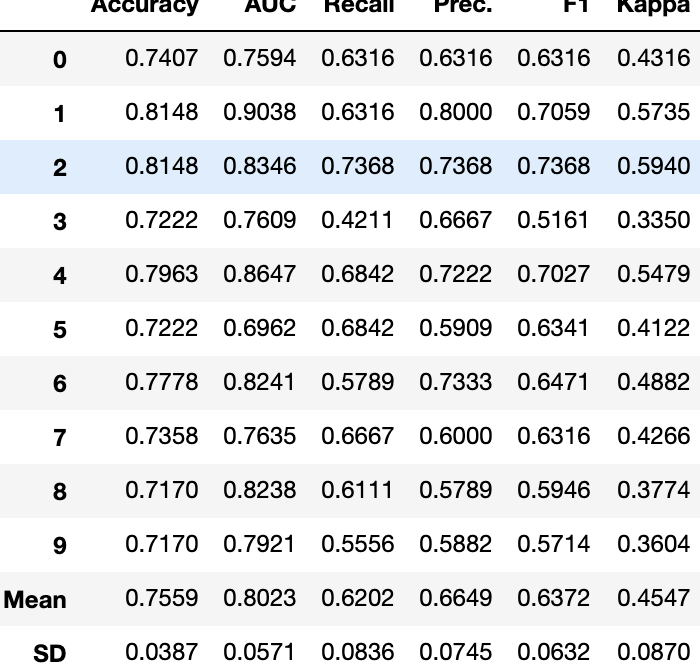
分类示例
# 使用Pandas加载CSV
from pandas import read_csv
# Importing dataset
diabetes = read_csv('diabetes.csv')
# Importing module and initializing setup
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# tuning LightGBM Model
tuned_lightgbm = tune_model('lightgbm')

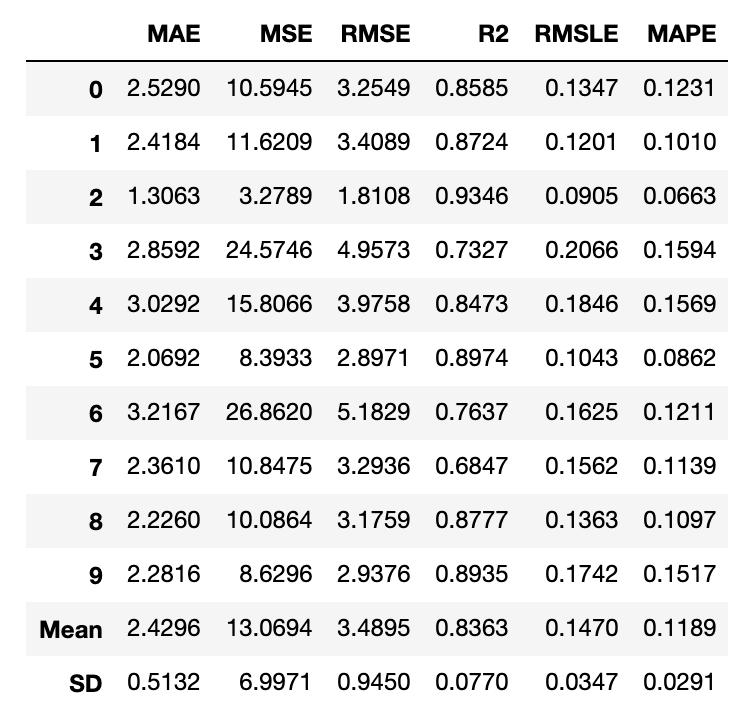
回归示例
# Importing dataset
boston = read_csv('boston.csv')
# Importing module and initializing setup
from pycaret.regression import *
reg1 = setup(data = boston, target = 'medv')
# tuning Random Forest model
tuned_rf = tune_model('rf', n_iter = 50, optimize = 'mae')

聚类示例
# Importing dataset
diabetes = read_csv('diabetes.csv')
# Importing module and initializing setup
from pycaret.clustering import *
clu1 = setup(data = diabetes)
# Tuning K-Modes Model
tuned_kmodes = tune_model('kmodes', supervised_target = 'Class variable')
异常检测实例
# Importing dataset
boston = read_csv('boston.csv')
# Importing module and initializing setup
from pycaret.anomaly import *
ano1 = setup(data = boston)
# Tuning Isolation Forest Model
tuned_iforest = tune_model('iforest', supervised_target = 'medv')
集成模型
集成一个训练模型和编写集成模型一样简单。它只需要一个强制参数,即训练的模型对象。此函数返回一个表,其中包含经过k次交叉验证的常用评估指标得分以及经过训练的模型对象。使用的评估指标包括:
- 分类: Accuracy, AUC, Recall, Precision, F1, Kappa
- 回归: MAE, MSE, RMSE, R2, RMSLE, MAPE
在集成模型函数中,可以使用 fold 参数定义交叉次数。默认情况下,交叉设置为10,所有度量都四舍五入到四位小数,可以使用 round 参数进行更改。有两种方法可用于集成,可在集成模型函数中使用方法参数设置。这两种方法都需要对数据进行重新采样,并拟合多个估计量,因此可以使用 n_estimators 参数来控制估计量的数量。默认情况下,n_estimators 设置为10。
此函数仅在pycaret.classification和pycaret.regression模块中可用。
BAGGING
Bagging也称为Bootstrap聚合,是一种机器学习集成元算法,旨在提高用于统计分类和回归的机器学习算法的稳定性和准确性。它还可以减少差异,并有助于避免过度拟合。尽管它通常应用于决策树方法,但它可以与任何类型的方法一起使用。Bagging是模型平均方法的一个特例。
# Importing dataset
diabetes = read_csv('diabetes.csv')
# Importing module and initializing setup
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# creating decision tree model
dt = create_model('dt')
# ensembling decision tree model (bagging)
dt_bagged = ensemble_model(dt)
BOOSTING
Boosting是一种集成元算法,主要用于减少监督学习中的偏差和方差。Boosting是机器学习算法家族中的一员,它将弱学习者转化为强学习者。弱学习者被定义为只与真实分类稍微相关的分类器(它可以比随机猜测更好地标记示例)。相比之下,一个强的学习者是一个分类器,它与真正的分类是任意地密切相关的。
# Importing dataset
boston = read_csv('boston.csv')
# Importing module and initializing setup
from pycaret.regression import *
reg1 = setup(data = boston, target = 'medv')
# creating decision tree model
dt = create_model('dt')
# ensembling decision tree model (boosting)
dt_boosted = ensemble_model(dt, method = 'Boosting')
STACK
堆叠模型是一种使用元学习的整合方法。叠加的思想是建立一个元模型,使用多个基估计量的预测生成最终预测。PyCaret中的堆栈模型和编写 stack_models 一样简单。此函数使用 estimator_list 参数获取训练模型列表。所有这些模型构成叠加的基础层,它们的预测被用作元模型的输入,可以使用 meta_model 参数传递。如果未传递元模型,则默认使用线性模型。在分类的情况下,方法参数可用于定义“soft”或“hard”,其中软使用预测的投票概率,硬使用预测的标签。此函数返回一个表,其中包含经过k次交叉验证的常用评估指标得分以及经过训练的模型对象。使用的评估指标包括:
- 分类: Accuracy, AUC, Recall, Precision, F1, Kappa
- 回归:MAE, MSE, RMSE, R2, RMSLE, MAPE
可以使用 stack_models 函数中的 fold 参数定义交叉次数。默认情况下,交叉设置为10,所有度量都四舍五入到4位小数,可以在 stack_models 中使用round 参数进行更改。restack参数控制向元模型公开原始数据的能力。默认情况下,它设置为 True。当变为 False 时,元模型将只使用基本模型的预测来生成最终预测。
基本模型可以是单层的,也可以是多层的,在这种情况下,前一层的预测作为输入传递到下一层,直到它到达元模型,在元模型中,包括基本层在内的所有层的预测作为输入来生成最终预测。要在多层中堆叠模型,create_stacknet 函数接受 estimator_list 参数作为列表内的列表。所有其他参数都相同。请参阅下面使用 create_stacknet 函数的回归示例。
此函数仅在pycaret.classification和pycaret.regression模块中可用。
- 分类示例
# Importing dataset
diabetes = read_csv('diabetes.csv')
# Importing module and initializing setup
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# create individual models for stacking
ridge = create_model('ridge')
lda = create_model('lda'
gbc = create_model('gbc')
xgboost = create_model('xgboost')
# stacking models
stacker = stack_models(estimator_list = [ridge,lda,gbc], meta_model = xgboost)
- 回归示例
# Importing dataset
boston = read_csv('boston.csv')
# Importing module and initializing setup
from pycaret.regression import *
reg1 = setup(data = boston, target = 'medv')
# creating multiple models for multiple layer stacking
catboost = create_model('catboost')
et = create_model('et')
lightgbm = create_model('lightgbm')
xgboost = create_model('xgboost')
ada = create_model('ada')
rf = create_model('rf')
gbr = create_model('gbr')
# creating multiple layer stacking from specific models
stacknet = create_stacknet([[lightgbm, xgboost, ada], [et, gbr, catboost, rf]])
BLEND
混合模型是利用估计量之间的一致性来产生最终预测的一种集成方法。混合的思想是结合不同的机器学习算法,在分类的情况下使用多数票或平均预测概率来预测最终结果。PyCaret中的混合模型和编写 blend_models 一样简单。此函数可用于混合特定的训练模型,这些模型可在混合模型中使用estimator_list 参数传递,如果未传递列表,则将使用模型库中的所有模型。在分类的情况下,方法参数可用于定义“soft”或“hard”,其中软使用预测的投票概率,硬使用预测的标签。此函数返回一个表,其中包含经过k次交叉验证的常用评估指标得分以及经过训练的模型对象。使用的评估指标包括:
- 分类: Accuracy, AUC, Recall, Precision, F1, Kappa
- 回归: MAE, MSE, RMSE, R2, RMSLE, MAPE
可以使用 blend_models 函数中的 fold 参数定义交叉次数。默认情况下,交叉设置为10,所有度量都四舍五入到四位小数,可以在 blend_models 中使用round参数进行更改。
此函数仅在pycaret.classification和pycaret.regression模块中可用。
分类示例
# Importing dataset
diabetes = read_csv('diabetes.csv')
# Importing module and initializing setup
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# blending all models
blend_all = blend_models()
回归示例
# Importing dataset
boston = read_csv('boston.csv')
# Importing module and initializing setup
from pycaret.regression import *
reg1 = setup(data = boston, target = 'medv')
# creating multiple models for blending
dt = create_model('dt')
catboost = create_model('catboost')
lightgbm = create_model('lightgbm')
# blending specific models
blender = blend_models(estimator_list = [dt, catboost, lightgbm])
解释模型
显示模型
可以使用plot_model函数对经过训练的机器学习模型进行性能评估和诊断。它使用训练有素的模型对象和作图的类型作为plot_model函数中的字符串输入。
# 使用Pandas加载CSV
from pandas import read_csv
# Importing dataset
diabetes = read_csv('diabetes.csv')
# Importing module and initializing setup
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# creating a model
lr = create_model('lr')
# plotting a model
plot_model(lr)
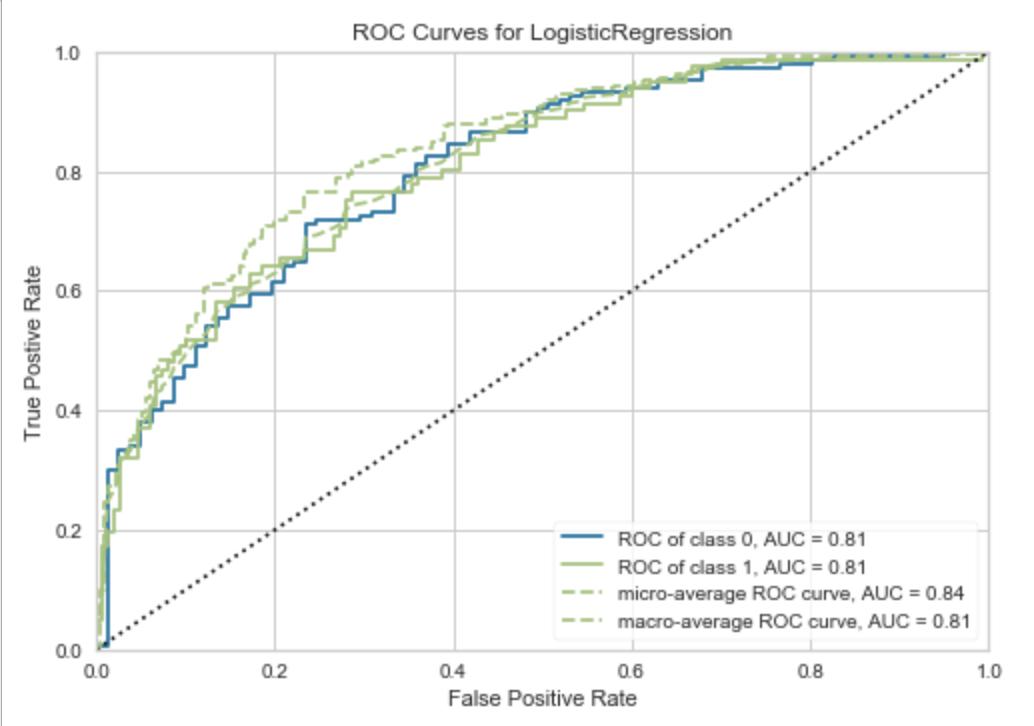

回归
# Importing dataset
boston = read_csv('boston.csv')
# Importing module and initializing setup
from pycaret.regression import *
reg1 = setup(data = boston, target = 'medv')
# creating a model
lr = create_model('lr')
# plotting a model
plot_model(lr)

聚类
# Importing dataset
jewellery = read_csv('jewellery.csv')
# Importing module and initializing setup
from pycaret.clustering import *
clu1 = setup(data = jewellery)
# creating a model
kmeans = create_model('kmeans')
# plotting a model
plot_model(kmeans)
解释模型
解释复杂模型在机器学习中具有重要意义。模型可解释性通过分析模型真正认为什么是重要的来帮助调试模型。PyCaret中的解释模型和编写 interpret_model 一样简单。函数以训练好的模型对象和绘图类型作为字符串。解释是基于SHAP(SHapley加法解释)实现的,仅适用于基于树的模型。
此函数仅在pycaret.classification和pycaret.regression模块中可用。
汇总图
在现实生活中通常是这样,当数据之间的关系是非线性时,我们总是看到基于树的模型(tree-based )比简单的高斯模型(simple gaussian models)做得更好。但是,这是以失去可解释性为代价的,因为基于树的模型没有像线性模型那样提供简单的系数。PyCaret 使用interpret_model函数实现SHAP(SHapley Additive exPlanations)。
# Importing dataset
diabetes = read_csv('diabetes.csv')
# Importing module and initializing setup
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# creating a model
xgboost = create_model('xgboost')
# interpreting model
interpret_model(xgboost)
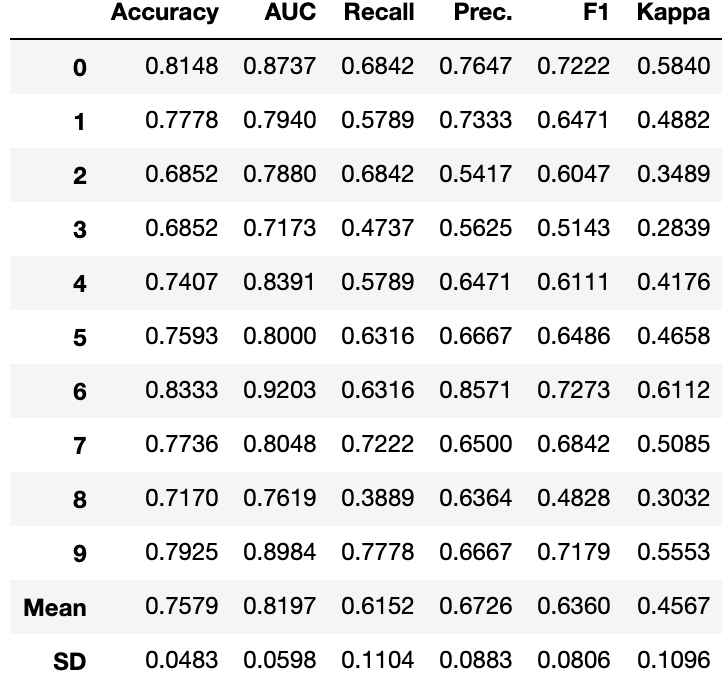


相关图
# Importing dataset
diabetes = read_csv('diabetes.csv')
# Importing module and initializing setup
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# creating a model
xgboost = create_model('xgboost')
# interpreting model
interpret_model(xgboost, plot = 'correlation')

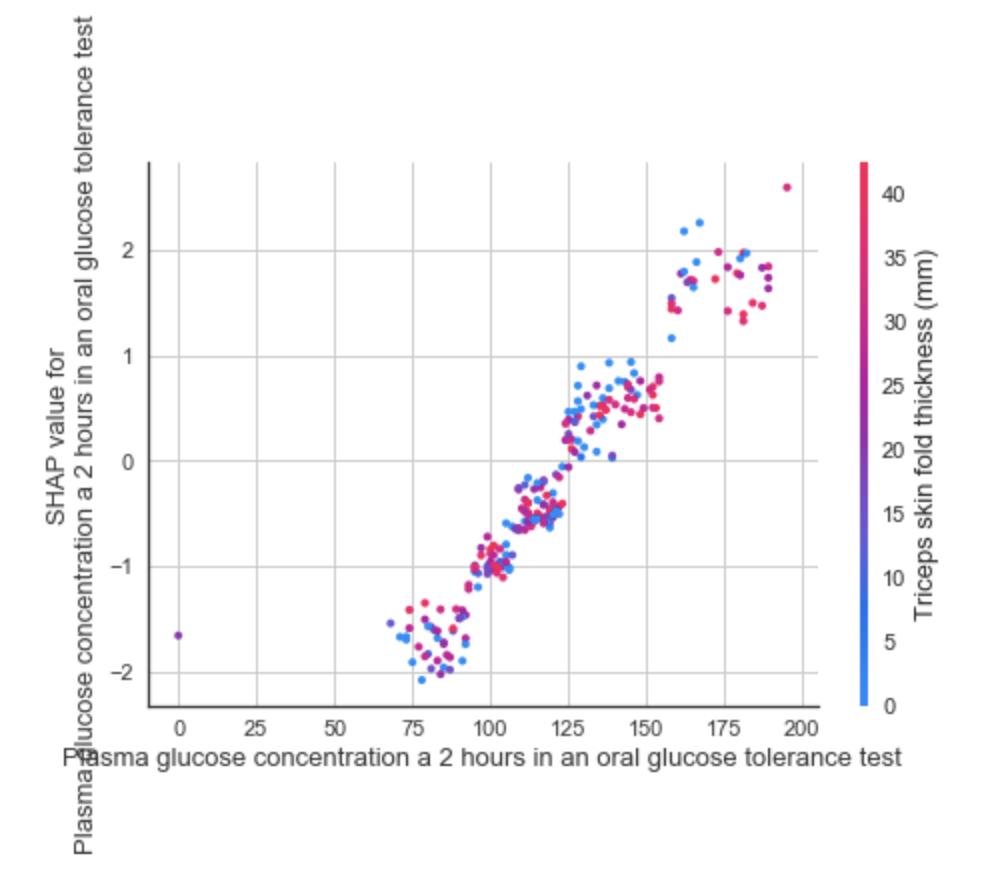

观察层面的因果图
可以使用“plot = ‘reason’”评估测试数据集中特定数据点(也称为原因自变量’reason argument’)的解释。在下面的示例中,我们正在检查测试数据集中的第一个实例。
# Importing dataset
diabetes = read_csv('diabetes.csv')
# Importing module and initializing setup
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# creating a model
xgboost = create_model('xgboost')
# interpreting model
interpret_model(xgboost, plot = 'reason', observation = 10)

分配模型
在执行无监督的实验(如聚类、异常检测)时,您通常对模型生成的标签感兴趣,例如,在聚类实验中,数据点所属的聚类标识是一个标签。同样,在异常检测实验中,哪一个观测值是离群值是一个二进制标签。这可以在PyCaret中使用 assign_model 函数来实现,该函数将经过训练的模型对象作为单个参数。
此函数仅在pycaret.clustering、pycaret.anomaly模块中可用。
- 聚类示例
# Importing dataset
jewellery = read_csv('jewellery.csv')
# Importing module and initializing setup
from pycaret.clustering import *
clu1 = setup(data = jewellery)
# create a model
kmeans = create_model('kmeans')
# Assign label
kmeans_results = assign_model(kmeans)
- 异常检测示例
# Importing dataset
anomaly = read_csv('anomaly.csv')
# Importing module and initializing setup
from pycaret.anomaly import *
ano1 = setup(data = anomaly)
# create a model
iforest = create_model('iforest')
# Assign label
iforest_results = assign_model(iforest)
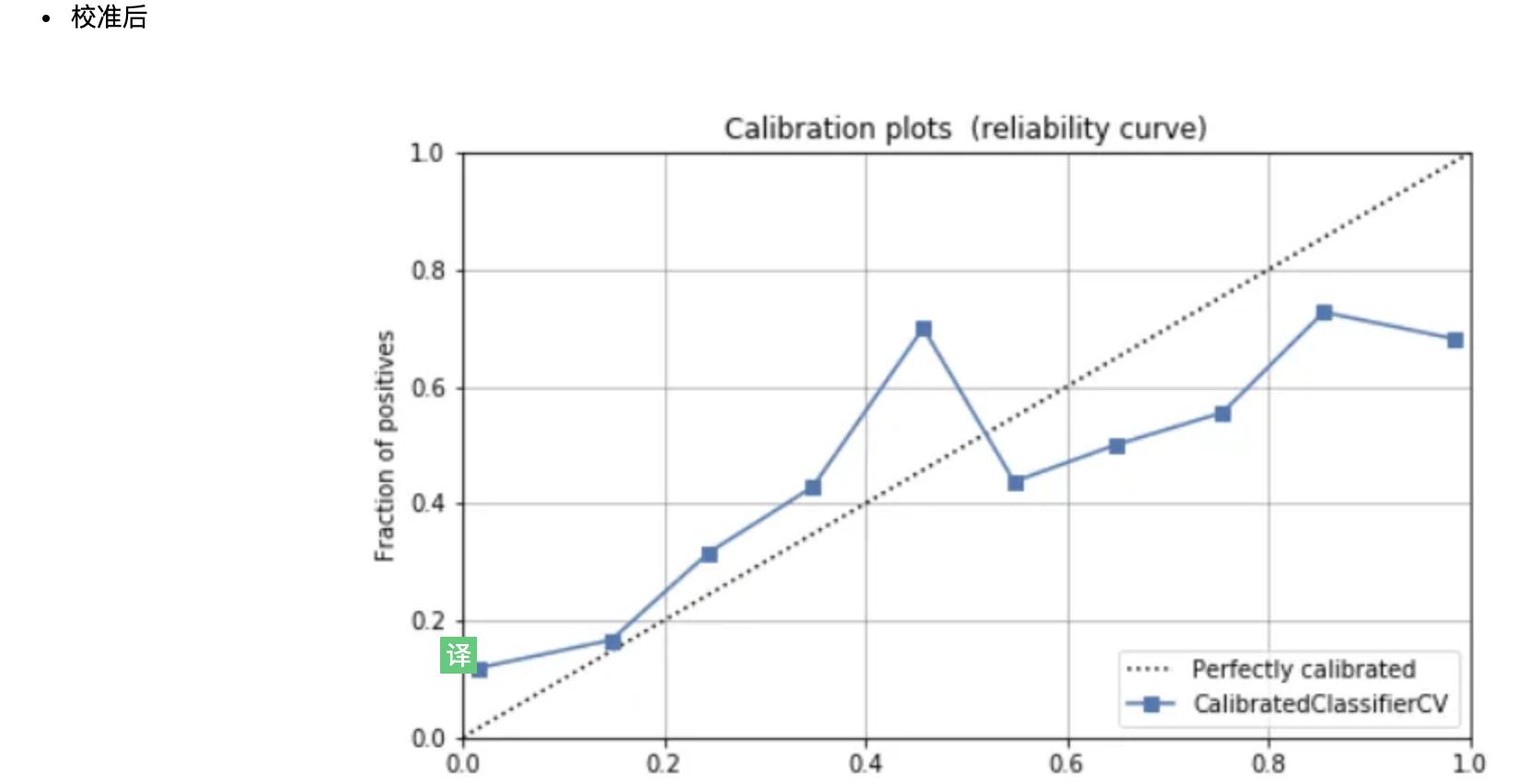
校准模型
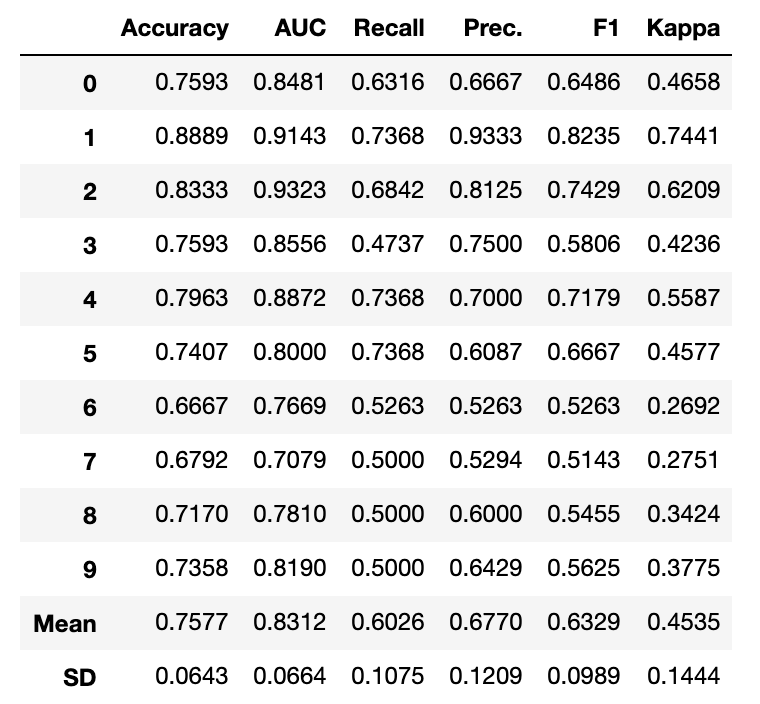
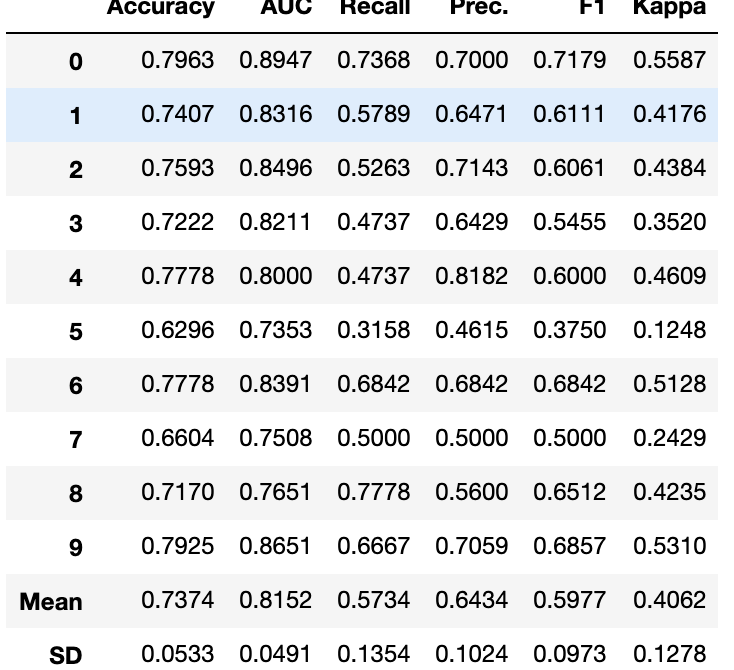
在进行分类实验时,通常不仅要预测类标签,还要获得预测的概率。这个概率给了你某种信心。一些模型可能会给你对类概率的糟糕估计。经过良好校准的分类器是概率分类器,其概率输出可以直接解释为一个置信水平。在PyCaret中校准分类模型和编写 calibrate_model 一样简单。函数通过方法参数选取训练好的模型对象和标定方法。方法可以是对应于Platt方法的“sigmoid”或非参数方法的“isotonic”。不建议在校准样品太少(<1000)的情况下使用等张校准,因为它容易过拟合。此函数返回一个表,其中包含k倍交叉验证的分类评估指标得分(Accuracy, AUC, Recall, Precision, F1 and Kappa)以及训练的模型对象。
在 calibrate_model 函数中,可以使用 fold 参数定义交叉次数。默认情况下,交叉设置为10,所有指标都四舍五入到4位小数,可以使用calibrate_模型中的round参数进行更改。
此函数仅在pycaret.classification模块中可用。
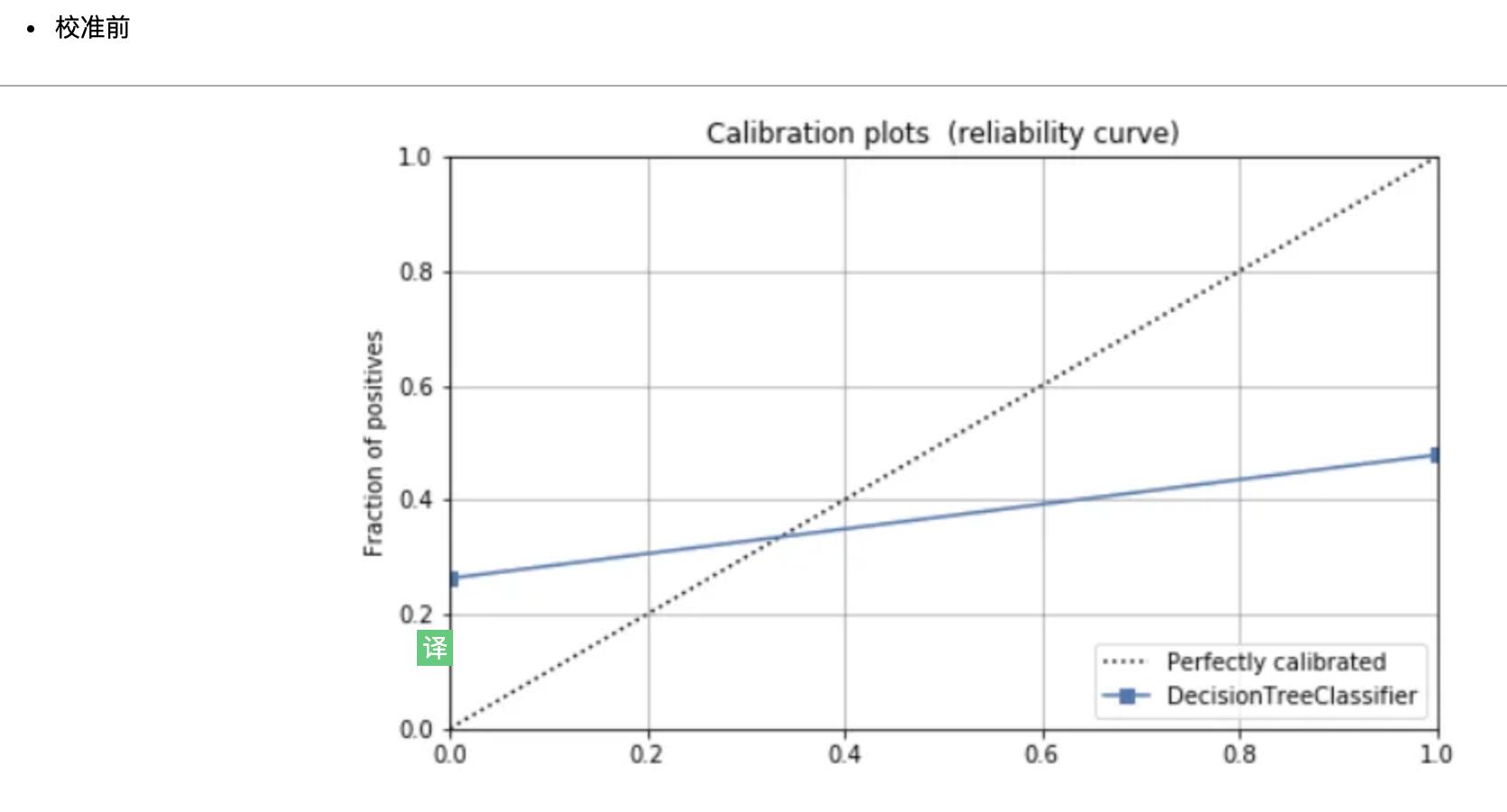


# Importing dataset
diabetes = read_csv('diabetes.csv')
# Importing module and initializing setup
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# create a model
dt = create_model('dt')
# calibrate a model
calibrated_dt = calibrate_model(dt)

优化阈值
在分类问题中,false positives 的代价几乎不等于 false negatives 的代价。因此,如果您正在优化 Type 1 和 Type 2 错误具有不同影响的业务问题,则可以a针对概率阈值优化分类器,以便通过分别定义真阳性、真阴性、假阳性和假阴性的成本来优化自定义损失函数。PyCaret中的优化阈值与编写 optimize_threshold 一样简单。它需要一个经过训练的模型对象(一个分类器),损失函数简单地由真阳性、真阴性、假阳性和假阴性表示。此函数返回一个交互图,其中损失函数(y轴)表示为x轴上不同概率阈值的函数。然后显示一条垂直线来表示该特定分类器的概率阈值的最佳值。然后,使用优化阈值优化的概率阈值可用于预测模型函数中,以使用自定义概率阈值生成标签。一般情况下,所有的分类器都被训练成50%的预测阳性类。
此函数仅在pycaret.classification模块中可用。
# Importing dataset
credit = read_csv('credit.csv')
# Importing module and initializing setup
from pycaret.classification import *
clf1 = setup(data = credit, target = 'default')
# create a model
xgboost = create_model('xgboost')
# optimize threshold for trained model
optimize_threshold(xgboost, true_negative = 1500, false_negative = -5000)

预测模型
到目前为止,我们看到的结果仅基于训练数据集的k倍交叉验证(默认为70%)。为了查看模型在test / hold-out上的预测和性能,使用了predict_model函数。
一旦使用 deploy_model 成功地将模型部署到云上,或者使用 save_model 成功地部署到本地,就可以使用 predict_model 函数对未显示的数据进行预测。这个函数需要一个经过训练的模型对象和数据集进行预测。它将自动应用在实验期间创建的整个转换管道。对于分类,预测标签是基于50%的概率创建的,但是如果您选择使用使用 optimize_threshold 获得的不同阈值,则可以在predict_model 中传递 probability_threshold 参数。此函数还可用于生成样本外/测试集的预测。
# Importing dataset
diabetes = read_csv('diabetes.csv')
# Importing module and initializing setup
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# create a model
rf = create_model('rf')
# predict test / hold-out dataset
rf_holdout_pred = predict_model(rf)
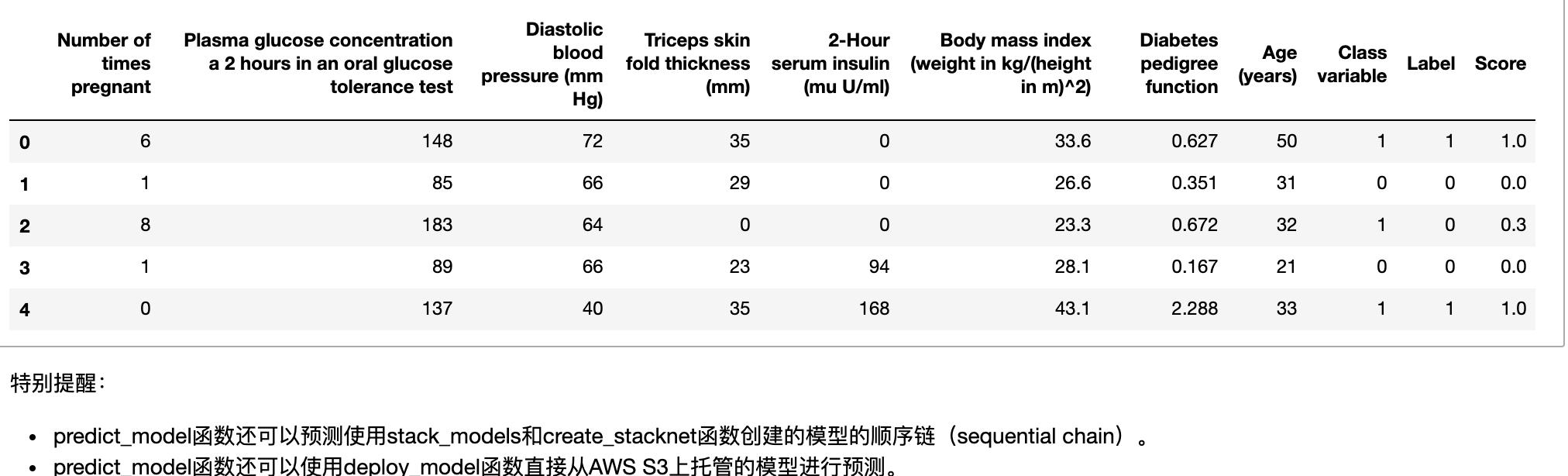
predict_model函数还用于预测未知的数据集。现在,我们将使用与训练时相同的数据集作为新的未知数据集的代理(proxy )。实际上,每次使用新的未知数据集时,predict_model函数将被迭代使用。
predictions = predict_model(rf, data = diabetes)
predictions.head()

部署模型
定型模型
定型模型是典型的监督实验流程的最后一步。使用setup在PyCaret中启动实验时,将创建一个在模型训练中不使用的保持集。默认情况下,如果设置中未定义 train_size 参数,则保持集包含30%的数据集样本。PyCaret中的所有函数都将剩下的70%用作创建、调整或集成模型的训练集。因此,保持装置是最终保证,用于诊断过度/不足。但是,一旦使用predict_模型在等待集上生成预测,并且您选择部署特定模型,您就需要在整个数据集(包括等待)上最后一次训练您的模型。在整个数据集上完成模型和编写 finalize_model 一样简单。此函数接受经过训练的模型对象,并返回在整个数据集上经过训练的模型。
此函数仅在pycaret.classification和pycaret.regression模块中可用。
# Importing dataset
diabetes = read_csv('diabetes.csv')
# Importing module and initializing setup
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# create a model
rf = create_model('rf')
# finalize a model
final_rf = finalize_model(rf)
部署模型


# Importing dataset
diabetes = read_csv('diabetes.csv')
# Importing module and initializing setup
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# create a model
lr = create_model('lr')
# finalize a model
final_lr = finalize_model(lr)
# Deploy a model
deploy_model(final_lr, model_name = 'lr_aws', platform = 'aws', authentication = { 'bucket' : 'pycaret-test' })
使用部署模型的预测
# Importing unseen dataset
import pandas as pd
data_unseen = pd.read_csv('data_unseen.csv')
# Generate predictions using deployed model
from pycaret.classification import *
predictions = predict_model(model_name = 'lr_aws', data = data_unseen, platform = 'aws', authentication = { 'bucket' : 'pycaret-test' })
保存模型
训练完成后,包含所有预处理转换和训练后的模型对象的整个管道都可以保存为二进制pickle文件。
# creating model
adaboost = create_model('ada')
# saving model
save_model(adaboost, model_name = 'ada_for_deployment')
您还可以将包含所有中间输出的整个实验保存为一个二进制文件。
save_experiment(experiment_name = 'my_first_experiment')
特别提醒:您可以使用PyCaret所有模块中可用的load_model和load_experiment函数加载保存的模型和保存的实验。
# Loading the saved model
dt_saved = load_model('ada_for_deployment')# Loading saved experiment
experiment_saved = load_experiment('my_first_experiment')
版权声明:本文为qq_43627540原创文章,遵循?CC 4.0 BY-SA?版权协议,转载请附上原文出处链接和本声明。
本文来自CSDN,观点不代表一起大数据-技术文章心得立场,如若转载,请注明出处:https://blog.csdn.net/qq_43627540/article/details/107667298
注意:本文归作者所有,未经作者允许,不得转载

