来源 | Towards Data Science

-
我将使用托管在Kaggle上的UCIML公共存储库中的toy数据集(https://www.kaggle.com/uciml/pima-indians-diabetes-database);它有九列,包括目标变量。如果你想使用,GitHub笔记本链接如下:https://github.com/salma71/blog_post/blob/master/Evaluate_ML_models_with_ensamble.ipynb。 -
在处理时,我使用kaggle api获取数据集。如果你在Kaggle上没有帐户,只需下载数据集,并跳过笔记本中的这一部分。
-
在构建模型之前,我对数据集做了一些基本的预处理,比如插补缺失的数据,以避免错误。 -
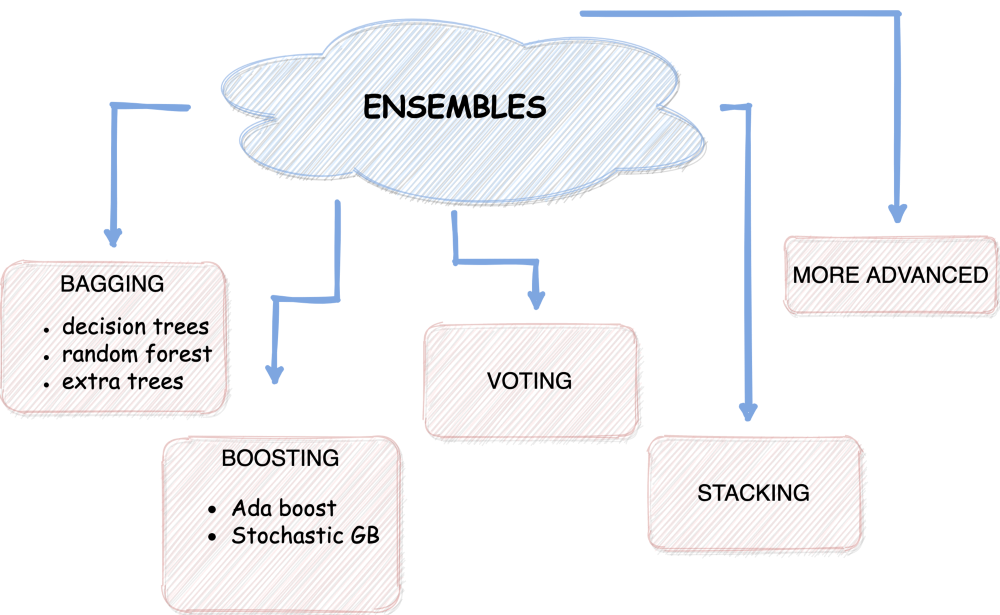
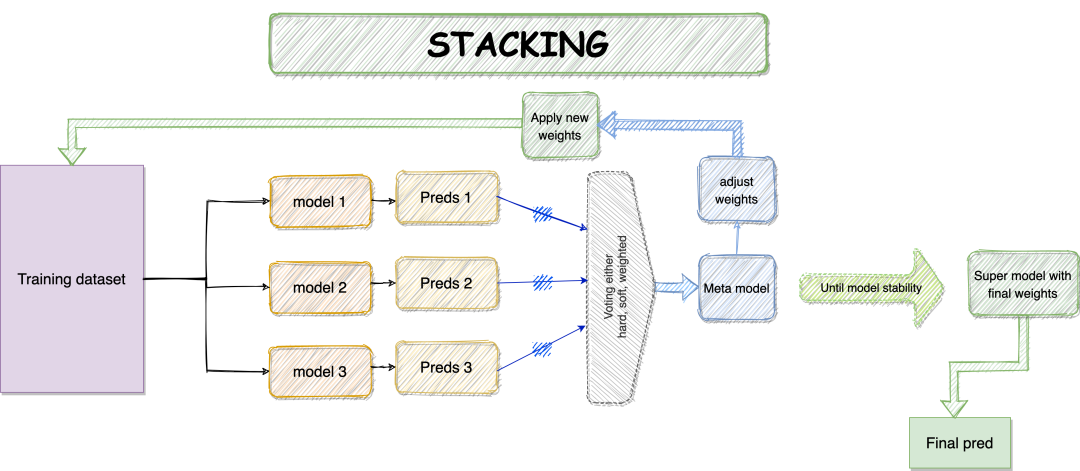
我创建了两个单独的笔记本,一个用来比较前三个集成模型。第二种方法是使用MLens库实现堆叠集成。

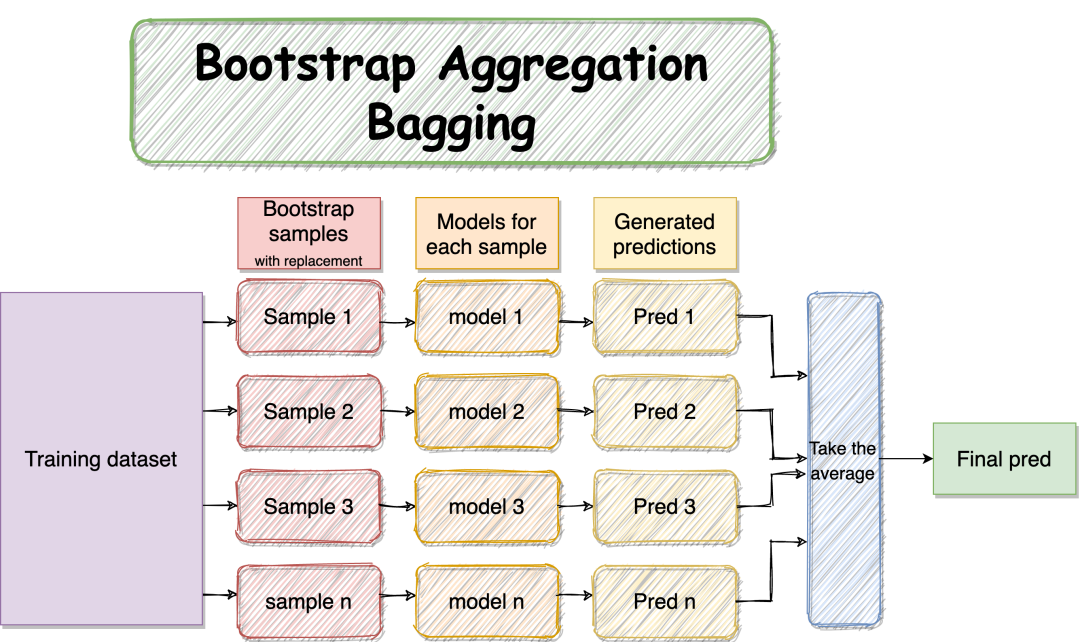

1.1Bagging决策树
tree = DecisionTreeClassifier()
bagging_clf = BaggingClassifier(base_estimator=tree, n_estimators=1500, random_state=42)
bagging_clf.fit(X_train, y_train)
evaluate(bagging_clf, X_train, X_test, y_train, y_test)
TRAINIG RESULTS:
===============================
CONFUSION MATRIX:
[[350 0]
[ 0 187]]
ACCURACY SCORE:
1.0000
CLASSIFICATION REPORT:
0 1 accuracy macro avg weighted avg
precision 1.0 1.0 1.0 1.0 1.0
recall 1.0 1.0 1.0 1.0 1.0
f1-score 1.0 1.0 1.0 1.0 1.0
support 350.0 187.0 1.0 537.0 537.0
TESTING RESULTS:
===============================
CONFUSION MATRIX:
[[126 24]
[ 38 43]]
ACCURACY SCORE:
0.7316
CLASSIFICATION REPORT:
0 1 accuracy macro avg weighted avg
precision 0.768293 0.641791 0.731602 0.705042 0.723935
recall 0.840000 0.530864 0.731602 0.685432 0.731602
f1-score 0.802548 0.581081 0.731602 0.691814 0.724891
support 150.000000 81.000000 0.731602 231.000000 231.000000
1.2 随机森林(RF)
rf_clf = RandomForestClassifier(random_state=42, n_estimators=1000)
rf_clf.fit(X_train, y_train)
evaluate(rf_clf, X_train, X_test, y_train, y_test)
TRAINIG RESULTS:
===============================
CONFUSION MATRIX:
[[350 0]
[ 0 187]]
ACCURACY SCORE:
1.0000
CLASSIFICATION REPORT:
0 1 accuracy macro avg weighted avg
precision 1.0 1.0 1.0 1.0 1.0
recall 1.0 1.0 1.0 1.0 1.0
f1-score 1.0 1.0 1.0 1.0 1.0
support 350.0 187.0 1.0 537.0 537.0
TESTING RESULTS:
===============================
CONFUSION MATRIX:
[[127 23]
[ 38 43]]
ACCURACY SCORE:
0.7359
CLASSIFICATION REPORT:
0 1 accuracy macro avg weighted avg
precision 0.769697 0.651515 0.735931 0.710606 0.728257
recall 0.846667 0.530864 0.735931 0.688765 0.735931
f1-score 0.806349 0.585034 0.735931 0.695692 0.728745
support 150.000000 81.000000 0.735931 231.000000 231.000000
1.3额外树(Extra trees,ET)
ex_tree_clf = ExtraTreesClassifier(n_estimators=1000, max_features=7, random_state=42)
ex_tree_clf.fit(X_train, y_train)
evaluate(ex_tree_clf, X_train, X_test, y_train, y_test)
TRAINIG RESULTS:
===============================
CONFUSION MATRIX:
[[350 0]
[ 0 187]]
ACCURACY SCORE:
1.0000
CLASSIFICATION REPORT:
0 1 accuracy macro avg weighted avg
precision 1.0 1.0 1.0 1.0 1.0
recall 1.0 1.0 1.0 1.0 1.0
f1-score 1.0 1.0 1.0 1.0 1.0
support 350.0 187.0 1.0 537.0 537.0
TESTING RESULTS:
===============================
CONFUSION MATRIX:
[[124 26]
[ 32 49]]
ACCURACY SCORE:
0.7489
CLASSIFICATION REPORT:
0 1 accuracy macro avg weighted avg
precision 0.794872 0.653333 0.748918 0.724103 0.745241
recall 0.826667 0.604938 0.748918 0.715802 0.748918
f1-score 0.810458 0.628205 0.748918 0.719331 0.746551
support 150.000000 81.000000 0.748918 231.000000 231.000000
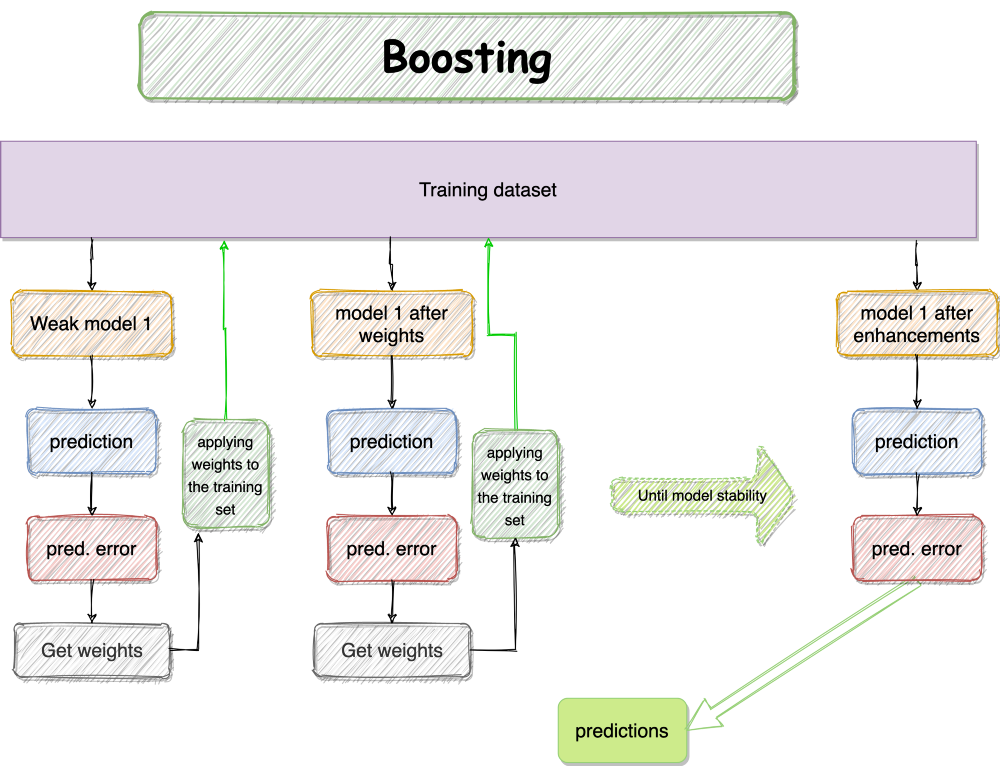

2.1 AdaBoost(AD)
ada_boost_clf = AdaBoostClassifier(n_estimators=30)
ada_boost_clf.fit(X_train, y_train)
evaluate(ada_boost_clf, X_train, X_test, y_train, y_test)
TRAINIG RESULTS:
===============================
CONFUSION MATRIX:
[[314 36]
[ 49 138]]
ACCURACY SCORE:
0.8417
CLASSIFICATION REPORT:
0 1 accuracy macro avg weighted avg
precision 0.865014 0.793103 0.841713 0.829059 0.839972
recall 0.897143 0.737968 0.841713 0.817555 0.841713
f1-score 0.880785 0.764543 0.841713 0.822664 0.840306
support 350.000000 187.000000 0.841713 537.000000 537.000000
TESTING RESULTS:
===============================
CONFUSION MATRIX:
[[129 21]
[ 36 45]]
ACCURACY SCORE:
0.7532
CLASSIFICATION REPORT:
0 1 accuracy macro avg weighted avg
precision 0.781818 0.681818 0.753247 0.731818 0.746753
recall 0.860000 0.555556 0.753247 0.707778 0.753247
f1-score 0.819048 0.612245 0.753247 0.715646 0.746532
support 150.000000 81.000000 0.753247 231.000000 231.000000
2.2 随机梯度增强(SGB)
grad_boost_clf = GradientBoostingClassifier(n_estimators=100, random_state=42)
grad_boost_clf.fit(X_train, y_train)
evaluate(grad_boost_clf, X_train, X_test, y_train, y_test)
TRAINIG RESULTS:
===============================
CONFUSION MATRIX:
[[339 11]
[ 26 161]]
ACCURACY SCORE:
0.9311
CLASSIFICATION REPORT:
0 1 accuracy macro avg weighted avg
precision 0.928767 0.936047 0.931099 0.932407 0.931302
recall 0.968571 0.860963 0.931099 0.914767 0.931099
f1-score 0.948252 0.896936 0.931099 0.922594 0.930382
support 350.000000 187.000000 0.931099 537.000000 537.000000
TESTING RESULTS:
===============================
CONFUSION MATRIX:
[[126 24]
[ 37 44]]
ACCURACY SCORE:
0.7359
CLASSIFICATION REPORT:
0 1 accuracy macro avg weighted avg
precision 0.773006 0.647059 0.735931 0.710032 0.728843
recall 0.840000 0.543210 0.735931 0.691605 0.735931
f1-score 0.805112 0.590604 0.735931 0.697858 0.729895
support 150.000000 81.000000 0.735931 231.000000 231.000000
-
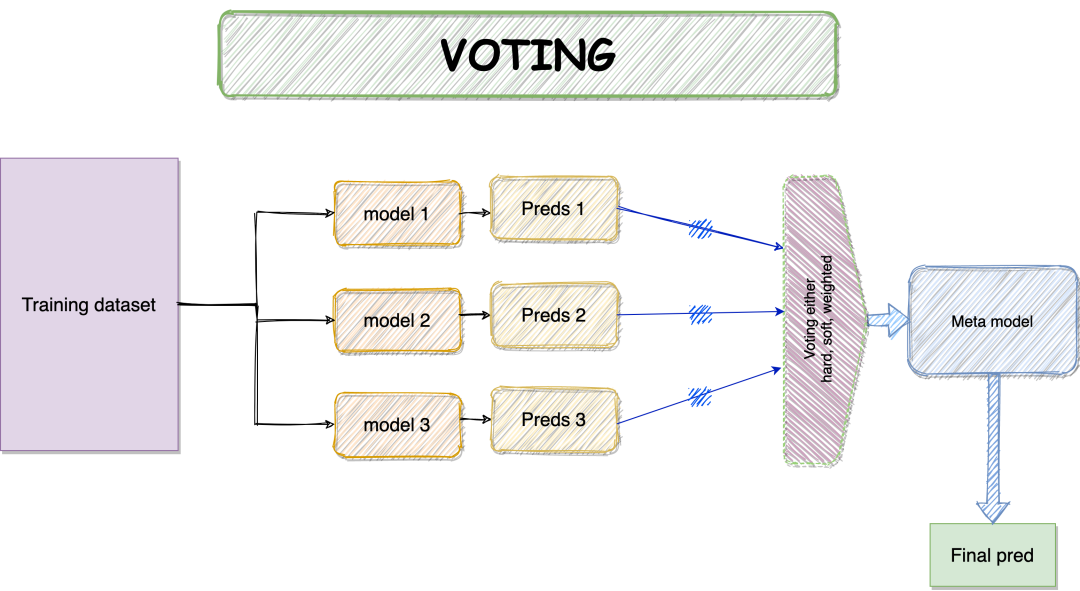
硬投票-大多数的类标签预测。 -
软投票-预测概率之和的argmax。 -
加权投票-预测概率加权和的argmax。

from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
estimators = []
log_reg = LogisticRegression(solver=’liblinear’)
estimators.append((‘Logistic’, log_reg))
tree = DecisionTreeClassifier()
estimators.append((‘Tree’, tree))
svm_clf = SVC(gamma=’scale’)
estimators.append((‘SVM’, svm_clf))
voting = VotingClassifier(estimators=estimators)
voting.fit(X_train, y_train)
evaluate(voting, X_train, X_test, y_train, y_test)
TRAINIG RESULTS:
===============================
CONFUSION MATRIX:
[[328 22]
[ 75 112]]
ACCURACY SCORE:
0.8194
CLASSIFICATION REPORT:
0 1 accuracy macro avg weighted avg
precision 0.813896 0.835821 0.819367 0.824858 0.821531
recall 0.937143 0.598930 0.819367 0.768037 0.819367
f1-score 0.871182 0.697819 0.819367 0.784501 0.810812
support 350.000000 187.000000 0.819367 537.000000 537.000000
TESTING RESULTS:
===============================
CONFUSION MATRIX:
[[135 15]
[ 40 41]]
ACCURACY SCORE:
0.7619
CLASSIFICATION REPORT:
0 1 accuracy macro avg weighted avg
precision 0.771429 0.732143 0.761905 0.751786 0.757653
recall 0.900000 0.506173 0.761905 0.703086 0.761905
f1-score 0.830769 0.598540 0.761905 0.714655 0.749338
support 150.000000 81.000000 0.761905 231.000000 231.000000

# 创建基础模型列表
def get_models():
models = list()
models.append(LogisticRegression(solver=’liblinear’))
models.append(DecisionTreeClassifier())
models.append(SVC(gamma=’scale’, probability=True))
models.append(GaussianNB())
models.append(KNeighborsClassifier())
models.append(AdaBoostClassifier())
models.append(BaggingClassifier(n_estimators=10))
models.append(RandomForestClassifier(n_estimators=10))
models.append(ExtraTreesClassifier(n_estimators=10))
return models
def get_super_learner(X):
ensemble = SuperLearner(scorer=accuracy_score,
folds = 10,
random_state=41)
model = get_models()
ensemble.add(model)
# 添加一些层
ensemble.add([LogisticRegression(), RandomForestClassifier()])
ensemble.add([LogisticRegression(), SVC()])
# 添加元模型
ensemble.add_meta(SVC())
return ensemble
# 超级学习者
ensemble = get_super_learner(X_train)
# 拟合
ensemble.fit(X_train, y_train)
# 摘要
print(ensemble.data)
# 预测
yhat = ensemble.predict(X_test)
print(‘Super Learner: %.3f’ % (accuracy_score(y_test, yhat) * 100))
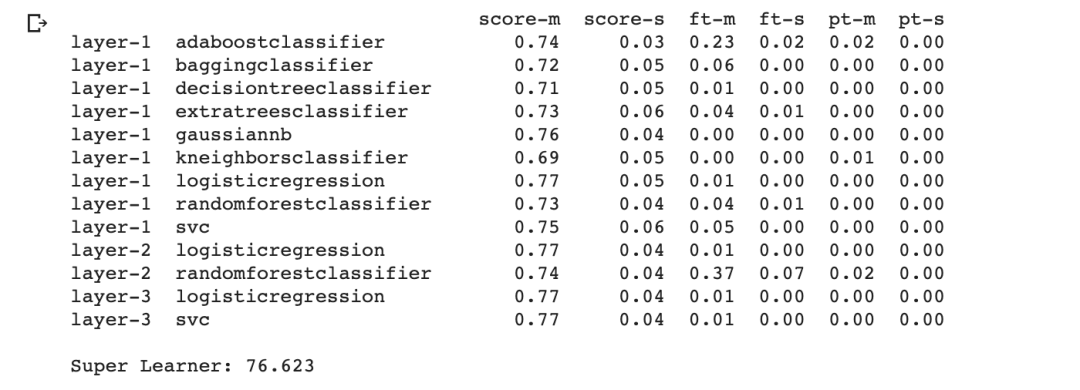

ACCURACY SCORE ON TEST: 76.62337662337663
fig = go.Figure()
fig.add_trace(go.Bar(
x = test[‘Algo’],
y = test[‘Train’],
text = test[‘Train’],
textposition=’auto’,
name = ‘Accuracy on Train set’,
marker_color = ‘indianred’))
fig.add_trace(go.Bar(
x = test[‘Algo’],
y = test[‘Test’],
text = test[‘Test’],
textposition=’auto’,
name = ‘Accuracy on Test set’,
marker_color = ‘lightsalmon’))
fig.update_traces(texttemplate=’%{text:.2f}’)
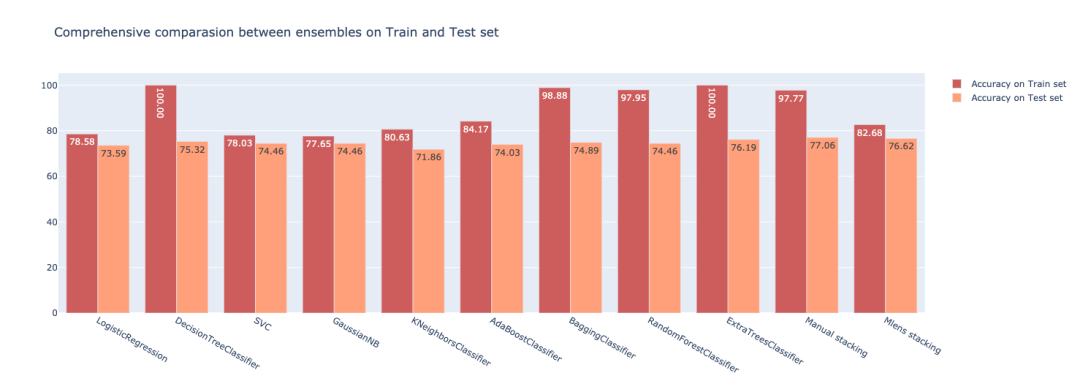
fig.update_layout(title_text=’Comprehensive comparasion between ensembles on Train and Test set’)
fig.show()

-
堆叠算法在精度、鲁棒性等方面都有提高,具有较好的泛化能力。 -
当我们想要设置性能良好的模型以平衡其弱点时,可以使用投票。 -
Boosting是一个很好的集成方法,它只是把多个弱的学习者结合起来,得到一个强大的学习者。 -
当你想通过组合不同的好模型来生成方差较小的模型时,可以考虑Bagging—减少过拟合。 -
选择合适的组合取决于业务问题和你想要的结果。
本文来自proginn.com,观点不代表一起大数据-技术文章心得立场,如若转载,请注明出处:https://jishuin.proginn.com/p/763bfbd5c09b
注意:本文归作者所有,未经作者允许,不得转载

