- 什么是Embedding?
- 推荐系统为什么需要Embedding?
- 推荐系统代码中如何用数据生成Embedding?
- 推荐系统代码中的Embedding技术分类有哪些?
1. 什么是Embedding?
Embedding往简单的说就是浮点数的“数组”(这个定义是我下的可能不一定准确,如,[0.2,0.4]这就是二维Embedding),往复杂了说就是用一个低维稠密的向量“表示”一个对象,这里所说的对象可以是一个词(Word2Vec),也可以是一个物品(Item2Vec),亦或是网络关系中的节点(Graph Embedding)。其中“表示”这个词意味着Embedding向量能够表达相应对象的某些特征,同时向量之间的距离反映了对象之间的相似性,说人话就是:Embedding实质上是反映了一种兴趣程度。
在 Embedding大行其道之前 oneHot才是最靓的仔。如果和我们比较熟悉的 oneHot 对比起来理解,顿时会发现 Embedding这个玄里玄乎的概念,实际上 so easy。直观上看 Embedding相当于是对 oneHot 做了平滑,而 oneHot 相当于是对 Embedding做了 max pooling。
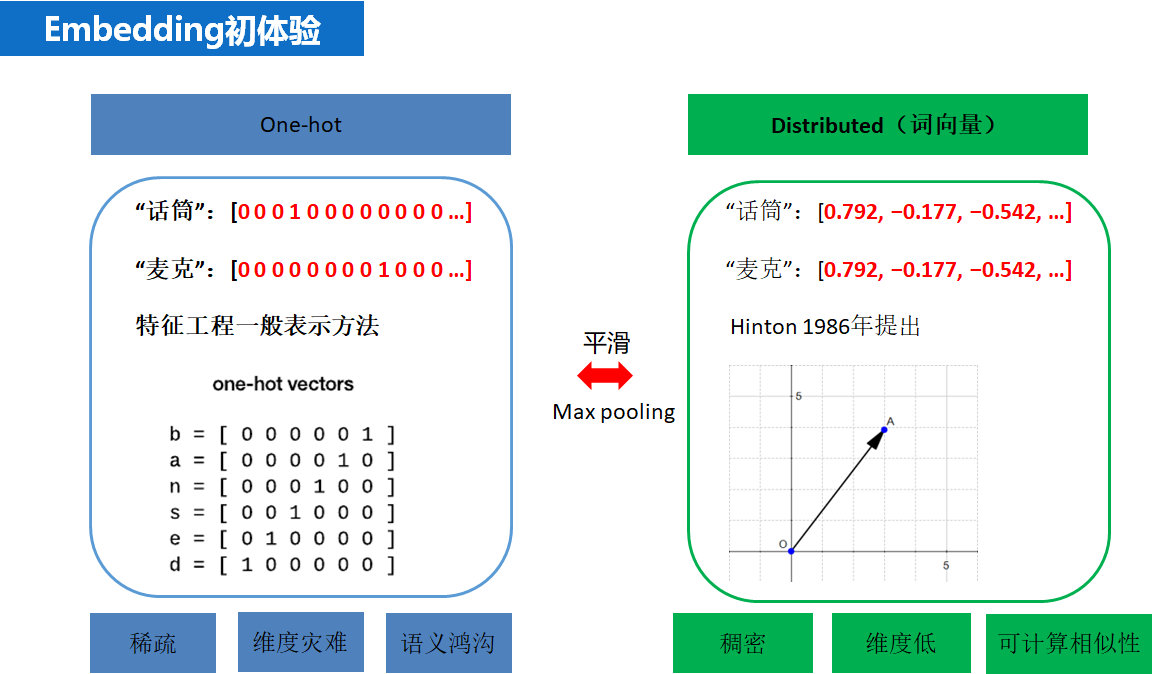

一般意义的 Embedding是神经网络倒数第二层的参数权重,只具有整体意义和相对意义(很重要!很重要!很重要!),不具备局部意义和绝对含义(所有又叫latent factor,隐向量,可以细看参考文献中——FM的DNN实现)。这与 Embedding的产生过程有关,任何 Embedding一开始都是一个随机数,然后随着优化算法,不断迭代更新,最后网络收敛停止迭代的时候,网络各个层的参数就相对固化,得到隐层权重表(此时就相当于得到了我们想要的 Embedding),然后在通过查表可以单独查看每个元素的 Embedding。
我解释一下为什么Embedding是神经网络倒数第二层的参数权重。首先,最后一层是预测层,倒数第二层与目标任务强相关,得到了Embedding,就可以用权重来表征该样本。其次,获得Embedding的目的是为了方便检索,检索实际上就是求距离最近,就是叉积最小。倒数第二层之前的隐层和倒数第二层的权重相乘可以理解为检索的过程,因为也是求叉积,而且一次性求了和所有候选item的叉积,所以可以拿Embedding直接做权重。
2. 推荐系统为什么需要Embedding?
当我们有了Embedding,我们就可以用近邻推推荐Nearest Neighbor(KNN并不低级,Youtube也是用这个)做到:物物推荐,人人推荐,人物推荐。
Embedding向量作为推荐算法中必不可少的部分,主要有四个运用方向:
(1)在深度学习网络中作为Embedding层,完成从高维稀疏特征向量到低维稠密特征向量的转换(比如Wide&Deep、DIN等模型)。 推荐场景中大量使用One-hot编码对类别、Id型特征进行编码,导致样本特征向量极度稀疏,而深度学习的结构特点使其不利于稀疏特征向量的处理,因此几乎所有的深度学习推荐模型都会由Embedding层负责将高维稀疏特征向量转换成稠密低维特征向量。因此,掌握各类Embedding技术是构建深度学习推荐模型的基础性操作。
(2)作为预训练的Embedding特征向量,与其他特征向量连接后,一同输入深度学习网络进行训练(比如FNN模型)。 Embedding本身就是极其重要的特征向量。相比MF矩阵分解等传统方法产生的特征向量,Embedding的表达能力更强,特别是Graph Embedding技术被提出后,Embedding几乎可以引入任何信息进行编码,使其本身就包含大量有价值的信息。在此基础上,Embedding向量往往会与其他推荐系统特征连接后一同输入后续深度学习网络进行训练。
(3)通过计算用户和物品的Embedding相似度,Embedding可以直接作为推荐系统的召回层或者召回策略之一(比如Youtube推荐模型等)。 Embedding对物品、用户相似度的计算是常用的推荐系统召回层技术。在局部敏感哈希(Locality-Sensitive Hashing)等快速最近邻搜索技术应用于推荐系统后,Embedding更适用于对海量备选物品进行快速“筛选”,过滤出几百到几千量级的物品交由深度学习网络进行“精排”。
YouTube 是利用 embedding 特征做推荐的开山之作,论文中user_vec是通过DNN学习到的,而引入DNN的好处则是任意的连续特征和离散特征可以很容易添加到模型当中。同样的,推荐系统常用的矩阵分解方法虽然也能得到user_vec和item_vec,但同样是不能Embedding嵌入更多feature。
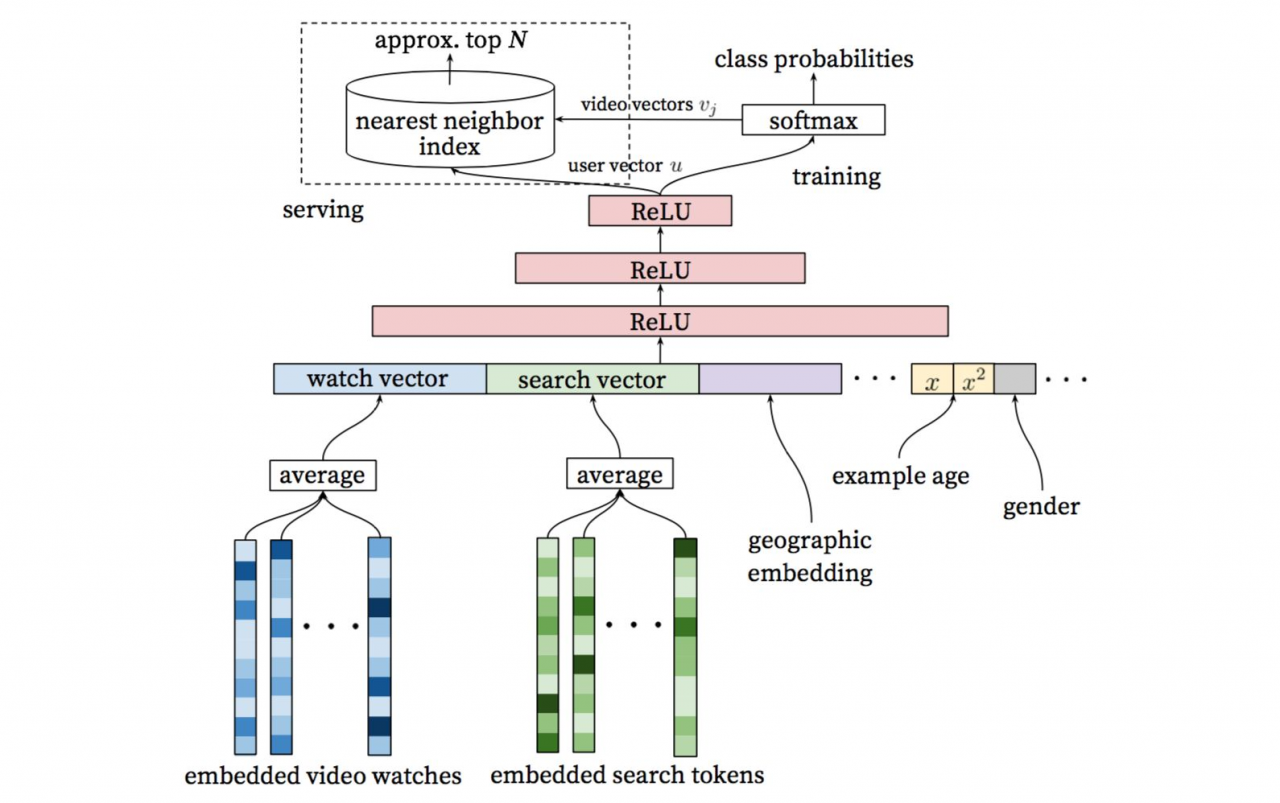

1.整个模型架构是包含三个隐层的DNN结构。输入是用户浏览历史watch vector、搜索历史search vector、人口统计学信息gender,age和其余上下文信息concat成的输入向量;输出分:线上和离线训练两个部分。
2.类似于word2vec的做法,每个视频都会被Embedding到固定维度的向量中。用户的观看视频历史则是通过变长的视频序列表达,最终通过加权平均(可根据重要性和时间进行加权)得到固定维度的watch vector作为DNN的输入。
3.离线训练阶段输出层为softmax层,而线上则直接利用user向量查询相关商品。模型进行serving的过程中,没有直接使用整个模型去做inference,而是直接使用user embedding和item embedding去做相似度的计算。其中user embedding是模型最后一层mlp的输出,video embedding则直接使用的是softmax的权重。
(4)通过计算用户和物品的Embedding,将其作为实时特征输入到推荐或者搜索模型中(比如Airbnb的Embedding应用)。值得一提的,就是以前的Embedding都是离线计算的,但是在2017年facebook发布了faiss算法,就可以流式添加Embedding,然后百万数据量的计算缩短在毫秒ms级了。
2018年Airbnb 论文主要贡献是在稀疏样本的构造上有所创新, Airbnb 这个操作部分弥补了 YouTube 在新闻推荐领域水土不服的问题。从一个 Embedding主义者的角度看,他的创新点主要有一下两点,一个是分群 embedding,另一个是用户和 item 混合训练。

3. 推荐系统代码中如何用数据生成Embedding?
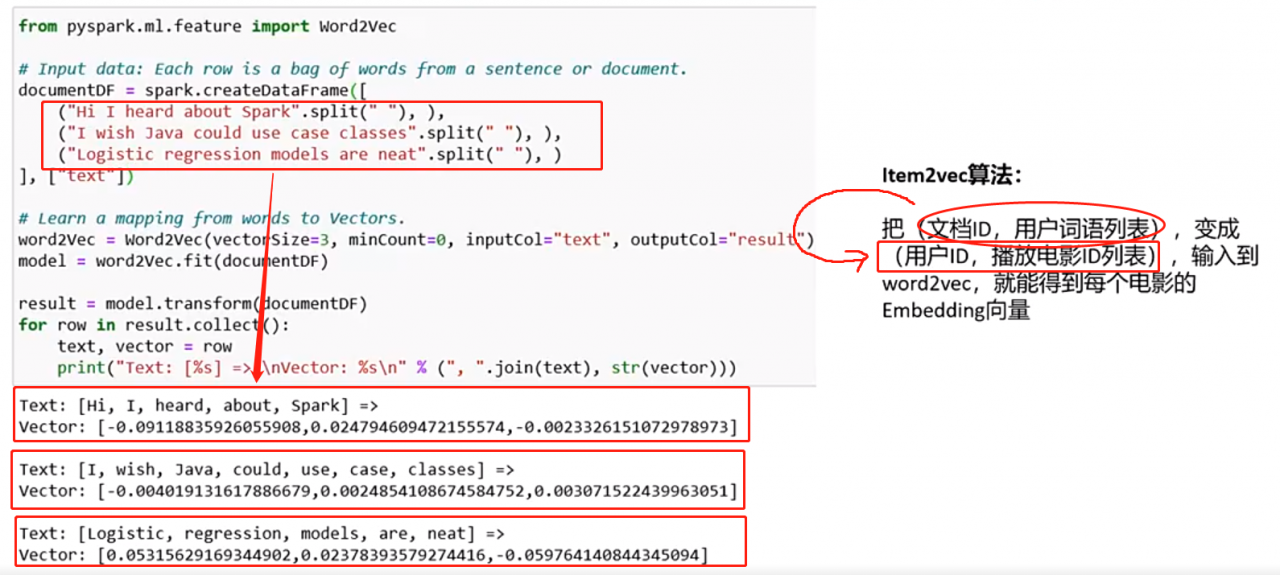
结合上图,罗列3个代码片段来说一下具体Embedding是怎么计算的?这3个场景分别为:word2vec、系统过滤和DNN。
3.1 基于内容的word2vec
先看红色方框有3句话是做为输入。然后word2vec就算了每个词的Embedding。
然后右边,我们可以把文档换成用户,词语换成电影,那么得到电影的推荐了。

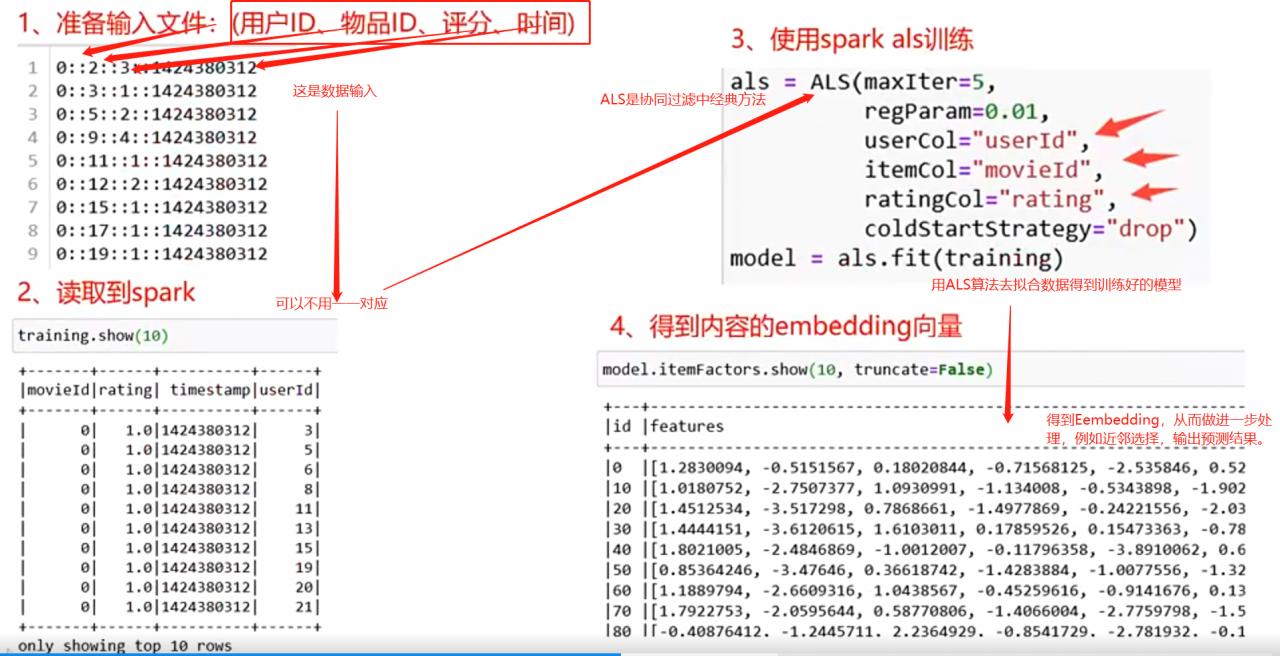
3.2 协同过滤矩阵的分解方法
其实指定输入的“用户id”,“电影id”,“评分”,然后fit,就的得到了每个item(表中的id电影)的Embedding向量(表中的features)。
因为他们都是行文相关的,那就可以物物推荐,人人推荐,人物推荐。

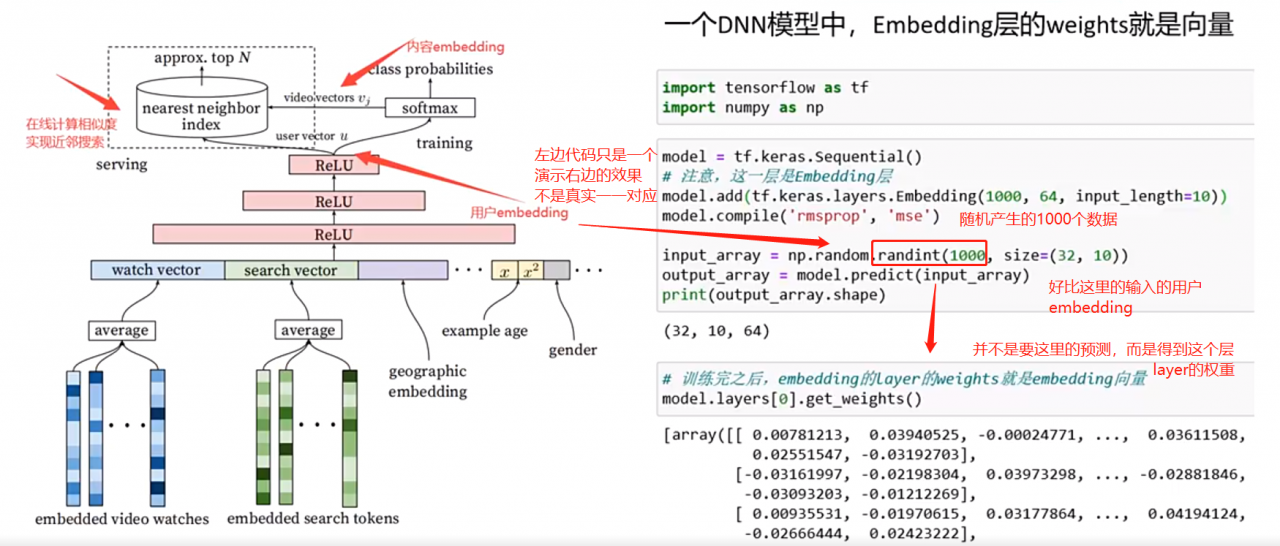
3.3 DNN深度学习的方法
其实上面特别说了一下,这里在细节说一下。Embedding其实是DNN的副产品。
什么意思呢?下面左边这个图,红色箭头指的Relu,其实包含了256个向量,其实这个256向量就是Embedding,这个Embedding就是权重。
然后最左边得到 video的向量,配合着Nearest Neighbor就能把通过Embedding权重计算的结果一起送去softmax最后输出预测top N。
是不是感觉似曾相识?其实transformer也是类似,利用QW的计算权重赋给V,然后送给softmax,唯一区别在于这里用DNN,而transformer用的是多头attention。

4. 推荐系统代码中的Embedding技术分类有哪些?
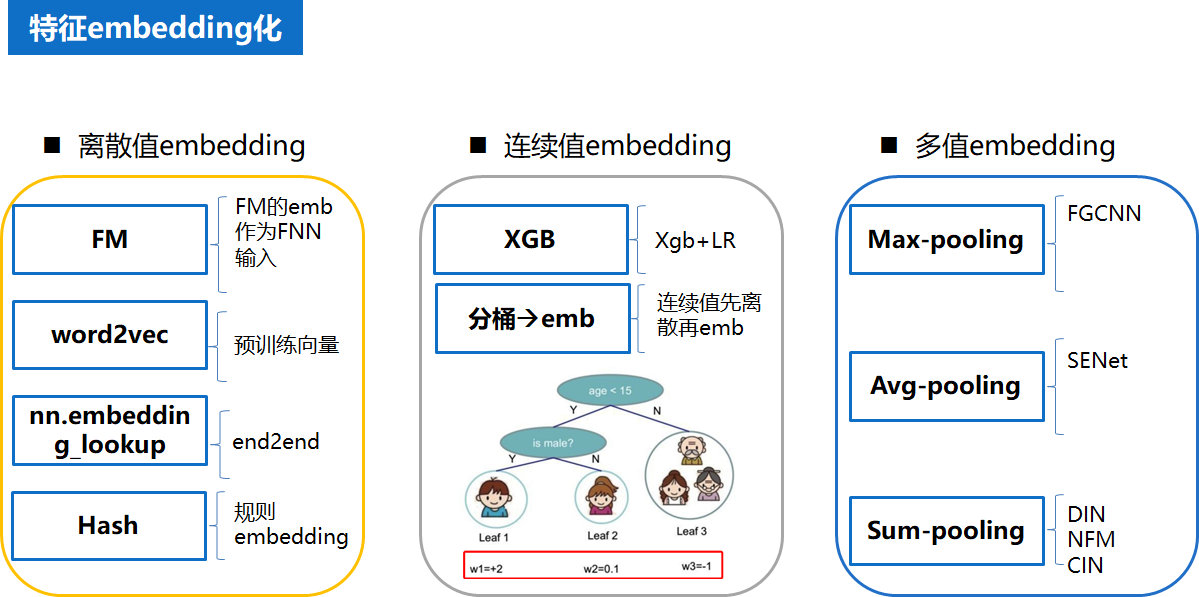
4.1 特征Embedding化
在特征工程中,对于离散值,连续值,多值大致有以下几种 Embedding的方法。预先训练的 Embedding特征向量,训练样本大,参数学习更充分。end2end 是通过 Embedding层完成从高维稀疏向量到低维稠密特征向量的转换,优点是端到端,梯度统一,缺点是参数多,收敛速度慢,如果数据量少,参数很难充分训练。

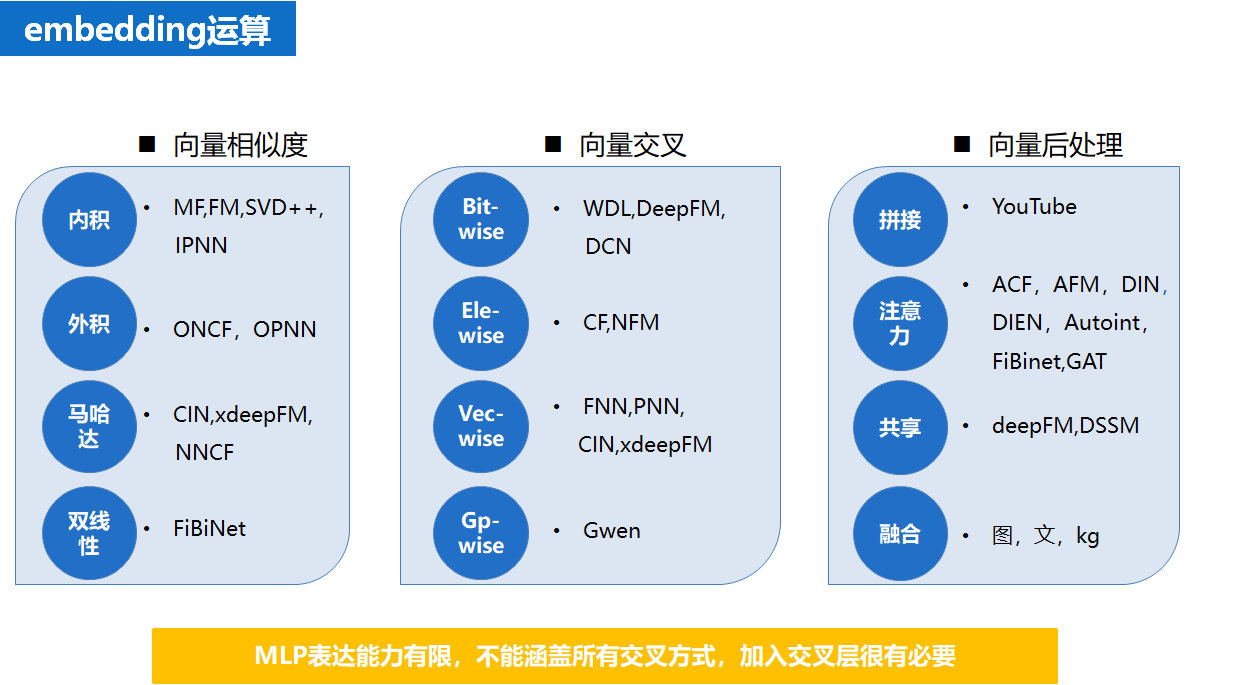
4.2 Embedding运算
不同的深度学习模型中,除了对网络结构的各种优化外,在 Embedding的运算上也进行了各种优化的尝试,对网络结构的各种优化本质上也是对 Embedding的运算的优化。

4.3 Embedding缺陷
Embedding作为一种技术,虽然很流行,但是他也存在一些缺陷,比如增量更新的语义不变性,很难同时包含多个特征,长尾数据难以训练等。
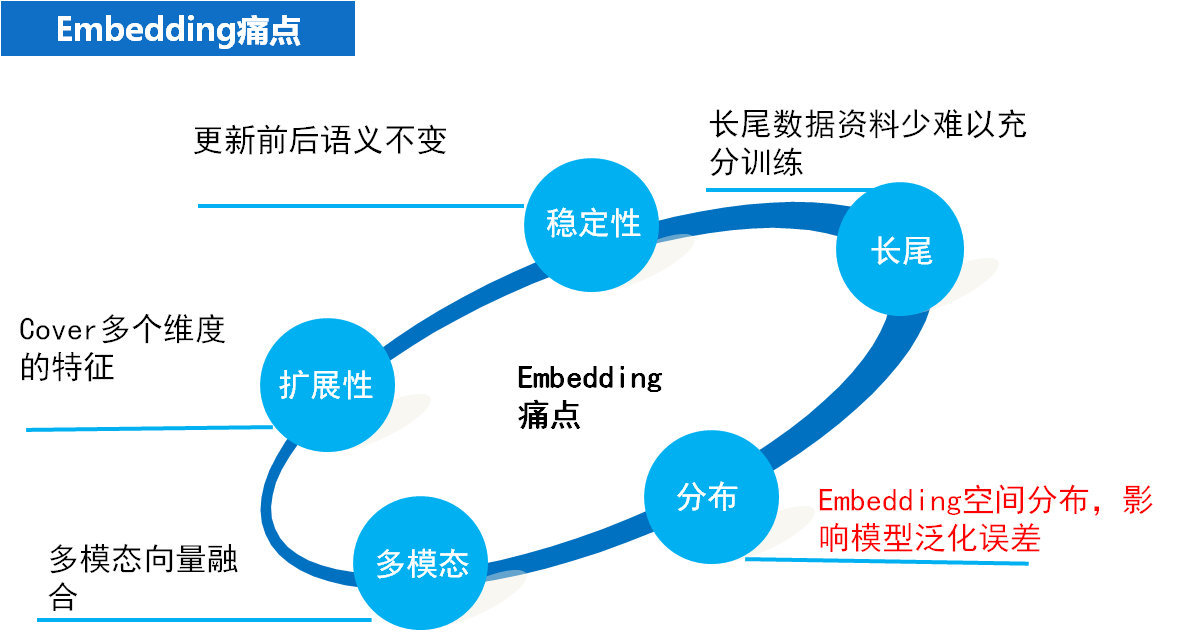

2020的KDD会议中,华为的一篇AutoFIS文章谈到了对Embedding持续优化,可以得到合适的特征向量化表达,同时得到内积“更合适”的值来表示组合特征的重要性。
其原理是在<Vi, Vj>前面增加了一个参数。我们可能会问再引入一个参数不是多此一举?我反而觉得这才是AutoFIS精华。Embedding的作用是将特征用向量化表示,并且保证相似特征的距离更近。基于此,相似特征内积就更大。而“相似”和“重要”是两码事,很“相似”的特征不一定能对预测起到更“重要”的作用。但是DeepFM在训练的过程中并没有将这两部分解耦,可能造成的结果就是Embedding的向量化表达不一定能让相似的特征距离更近,同时重要的特征内积也不一定大。

参考
深度学习推荐系统中各类流行的Embedding方法(上) – 云+社区 – 腾讯云 (tencent.com)
推荐系统 embedding 技术实践总结 – 知乎 (zhihu.com)
Deep Neural Network for YouTube Recommendation论文精读 – 知乎 (zhihu.com)
推荐系统中的embedding技术 – 知乎 (zhihu.com)
FM的DNN实现——隐向量可以认为就是embedding学习的权重程序大猩猩的博客-CSDN博客隐向量
作者:andyham
链接:https://www.jianshu.com/p/22c19af424ec
本文来自简书,观点不代表一起大数据-技术文章心得立场,如若转载,请注明出处:https://www.jianshu.com/p/22c19af424ec
注意:本文归作者所有,未经作者允许,不得转载

